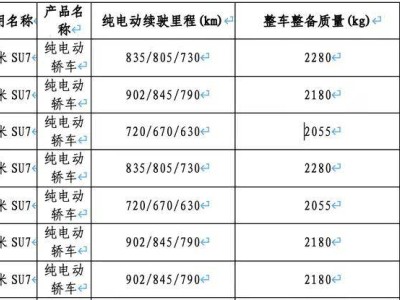
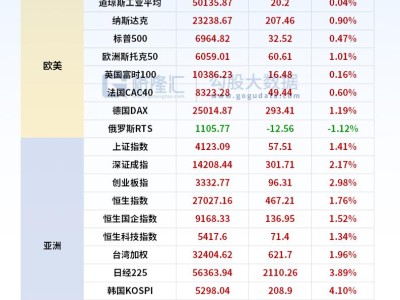
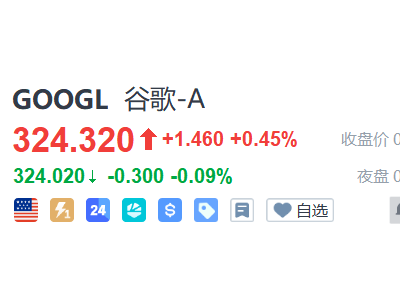
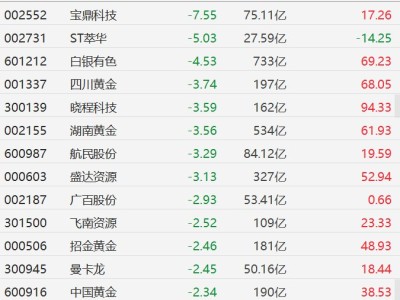
千問團隊近日正式發(fā)布新一代圖像生成基礎(chǔ)模型Qwen-Image-2.0,該模型創(chuàng)新性整合了文生圖與圖生圖功能,在文字渲染精度、圖像細節(jié)表現(xiàn)和語義理解能力上取得顯著突破。通過優(yōu)化算法架構(gòu),模型可同時處理1024個token的復雜指令輸入,支持生成包含PPT、海報、漫畫在內(nèi)的多種專業(yè)信息圖表,滿足不同場景的創(chuàng)作需求。
在圖像質(zhì)量方面,新模型實現(xiàn)2K分辨率輸出,特別強化了人物面部特征、自然景觀紋理和建筑結(jié)構(gòu)細節(jié)的還原能力。測試數(shù)據(jù)顯示,模型在處理寫實類場景時,光影層次和材質(zhì)表現(xiàn)較前代提升37%,能夠精準呈現(xiàn)金屬反光、布料褶皺等微觀細節(jié)。其獨創(chuàng)的"畫中畫"構(gòu)圖功能,可自動識別主體與背景關(guān)系,生成具有空間層次感的復合圖像。
AI Arena平臺的盲測結(jié)果顯示,Qwen-Image-2.0在文生圖基準測試中以1029分位列全球第三,在圖片編輯專項測試中取得1034分,僅次于專業(yè)級模型Nano Banana Pro。該模型在延續(xù)文字渲染優(yōu)勢的基礎(chǔ)上,新增了智能補全功能,當用戶修改圖像局部時,系統(tǒng)可自動協(xié)調(diào)整體風格與細節(jié),確保修改區(qū)域與原圖無縫融合。
技術(shù)團隊透露,新模型采用輕量化設(shè)計,參數(shù)規(guī)模較同類產(chǎn)品減少23%,但生成速度提升1.8倍。通過動態(tài)計算分配機制,模型可根據(jù)任務(wù)復雜度自動調(diào)整算力消耗,在保持高質(zhì)量輸出的同時降低硬件門檻。目前該模型已開放API接口,支持開發(fā)者進行二次開發(fā),后續(xù)將推出移動端適配版本。