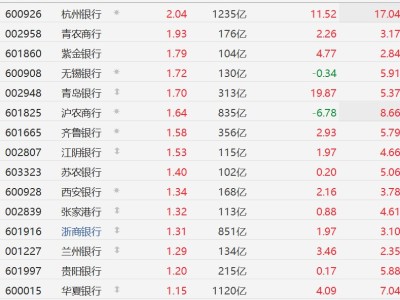
3 月 12 日消息,英偉達公司昨日(3 月 11 日)發布博文,宣布推出 Nemotron 3 Super 開源大模型,是其迄今為止最強大的開源權重 AI 模型。
注:開源權重模型(Open-weight AI models)是指將決定 AI 模型行為的關鍵參數(權重)向公眾免費開放的模型。與完全閉源的模型(如 GPT-4)不同,開發者可以下載并在自己的設備上運行或微調這些模型。
Nemotron 3 Super 模型擁有 1200 億參數,采用混合專家(MoE)架構(推理時僅激活 120 億),專為大規模運行復雜智能體(Agentic AI)系統設計。
該模型結合了先進的推理能力,能夠為自主智能體高精度地完成任務。Perplexity、Palantir 和西門子等行業巨頭目前已將其應用于搜索、軟件開發、電信和半導體設計等核心工作流中。
隨著企業將 AI 應用從聊天機器人轉向多智能體,往往面臨兩大瓶頸:“上下文爆炸”與“推理稅”。多智能體交互會產生最多 15 倍的 Token 量,導致成本飆升和目標偏移;同時,復雜智能體每步都需要推理,讓系統變得昂貴且遲鈍。
Nemotron 3 Super 為解決這些問題,配備了 100 萬 Token 的上下文窗口。這讓智能體能夠將完整的工作流狀態保留在內存中,從而防止目標偏移,并大幅降低多步推理的成本。
在架構與性能方面,該模型采用了混合專家(MoE)架構,將吞吐量提升了 5 倍,準確率比前代翻倍。具體而言,其 Mamba 層使內存和計算效率提高了 4 倍,而 Transformer 層則負責高級推理。
模型引入了“潛在 MoE(Latent MoE)”新技術,以單個專家的計算成本激活四個專家;并支持多 Token 預測,讓推理速度提升 3 倍。在英偉達 Blackwell 平臺上,該模型以 NVFP4 精度運行,相比 Hopper 架構上的 FP8,內存需求更低且推理速度快 4 倍。
英偉達對該模型采取了高度開放的策略。官方不僅遵循寬松許可證開源了模型權重,還公布了完整的訓練方法,包括超 10 萬億 Token 的數據集和評估配方。在實際場景中,它能一次性加載完整代碼庫進行端到端調試,或瞬間讀取數千頁財務報告。
開發者目前可通過 Hugging Face、各大云服務商(谷歌云、甲骨文,及即將上線的 AWS 和 Azure)獲取該模型。同時,它已被打包為 NVIDIA NIM 微服務,支持無縫部署制本地數據中心和云端。