在近期一場國際技術盛會上,某科技公司創始人楊植麟首次公開了新一代大模型Kimi K2.5的技術演進路徑,其核心突破在于通過系統性重構底層架構,突破傳統規模化發展模式對算力資源的線性依賴。這一技術路線標志著行業正從"參數堆砌"轉向"效率革命",為人工智能發展開辟了新的可能性。
傳統大模型發展長期遵循"Scaling Law"原則,即通過擴大參數規模和算力投入提升模型能力。但研究團隊發現,當模型參數突破千億級后,單純增加硬件投入帶來的邊際效益顯著下降。Kimi團隊通過優化Token處理效率、重構注意力機制、改進殘差連接三大核心創新,實現了計算資源利用率質的飛躍。其中自主研發的Muon優化器,通過數值穩定性改進解決了傳統優化器在超大規模訓練中的Logits爆炸問題,使相同算力下的有效訓練量提升近一倍。
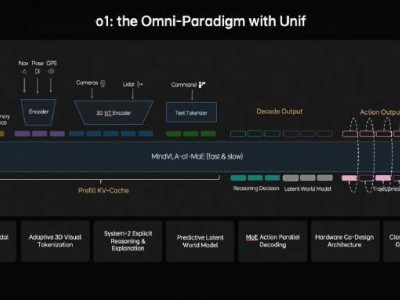
在架構創新層面,研究團隊對2017年提出的全注意力機制發起挑戰。新推出的KDA混合架構通過動態分配計算資源,在保持模型精度的同時,將超長上下文處理速度提升5-6倍。這種突破使得模型能夠高效處理128K甚至1M長度的文本輸入,在金融分析、法律文書處理等需要長程記憶的場景中展現出顯著優勢。更值得關注的是,團隊提出的注意力殘差連接方案,通過智能篩選歷史信息,有效解決了深層網絡中的信息衰減問題,為模型表達能力設立了新的基準。
系統級創新成為本次技術披露的最大亮點。Kimi K2.5引入的智能體集群架構,將復雜任務拆解為多個子任務,由不同專業智能體并行處理。通過設計的強化學習獎勵機制,確保各智能體既能獨立運作又能高效協同,避免了傳統多模型系統常見的效率損耗問題。實驗數據顯示,這種分布式協作模式在處理多步驟推理任務時,較單模型方案效率提升達300%。這種"系統級規模化"思路,為應對未來AI應用場景的復雜性提供了新范式。
跨模態能力融合方面,研究團隊發現視覺強化學習不僅能提升模型視覺認知水平,還能通過信息遷移反哺文本推理能力。在標準測試中,這種多模態訓練方式使文本任務性能提升2.1%,驗證了不同感知通道間存在可轉化的認知機制。該發現為開發通用人工智能提供了新思路,即通過構建模態間的認知橋梁,突破單一模態的能力邊界。
技術演進背后折射出行業發展的深層變革。隨著算力增長趨緩,提升單位算力產出成為競爭焦點。Kimi團隊通過重構訓練方法論,使"舊技術"在新架構中煥發新生。例如被行業沿用十年的Adam優化器,在新型數值穩定技術的加持下,計算效率實現代際躍升。這種"老技術新用"的實踐表明,人工智能發展正進入精細化創新階段,系統優化能力將成為決定技術競爭力的關鍵因素。
當前,全球科技企業都在探索大模型發展的新路徑。Kimi團隊提出的效率驅動模式,通過優化計算資源分配、重構基礎組件、創新系統架構三重突破,為行業提供了可復制的技術升級方案。這種發展思路的轉變,預示著人工智能競爭正從單一模型能力比拼,轉向涵蓋算法、架構、系統的全鏈條創新生態構建。