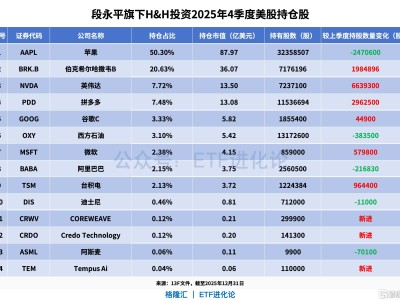
通義大模型官方公眾號近日對外宣布,其研發的Qwen-Image-2512模型正式開源。這一消息標志著圖像生成領域的技術迭代邁入新階段,該模型在視覺效果呈現上實現了突破性進展。
相較于今年8月發布的初代Qwen-Image模型,新版本在三大維度實現顯著優化。通過改進的生成算法,人物皮膚質感呈現更趨真實,能夠精準還原毛孔、汗毛等微觀細節;自然場景中的巖石、水流、植被等紋理表現力大幅提升,光影過渡更加自然;針對文字元素的渲染能力得到質的飛躍,可生成符合物理規律的立體字效,支持多語言混合排版與復雜排版布局。
技術團隊透露,此次升級采用多尺度特征融合架構,通過引入3D感知模塊增強空間層次感,同時優化注意力機制提升局部細節精度。在開源協議方面,研發方選擇完全開放的MIT許可,允許商業機構自由使用、修改及二次開發,此舉或將加速AI圖像技術在影視制作、游戲開發、廣告設計等領域的落地應用。
目前,模型代碼及預訓練權重已在主流開源平臺上線,配套發布的技術文檔詳細說明了訓練數據構成與微調指南。開發者社區反饋顯示,該模型在人物肖像生成、產品渲染圖制作等場景中展現出明顯優勢,部分測試案例的視覺效果已接近專業設計師水準。