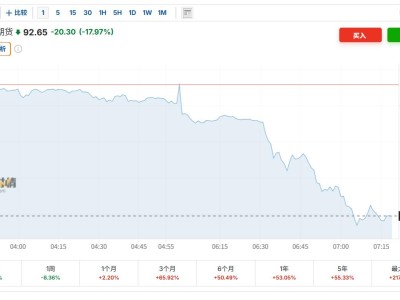
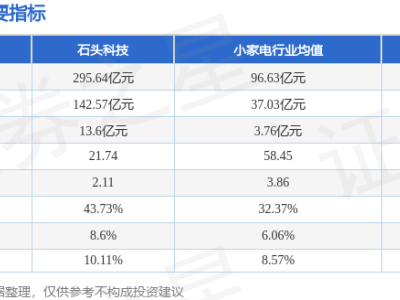
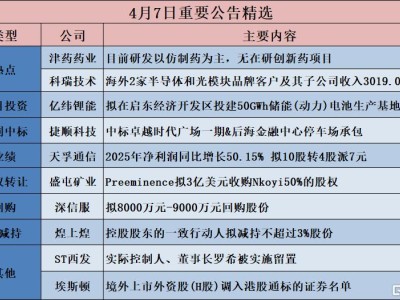
格隆匯2月16日|據(jù)新智元,一張圖在全網(wǎng)瘋狂刷屏了!據(jù)說(shuō),DeepSeek V4的基準(zhǔn)測(cè)試已經(jīng)泄露,整個(gè)AI圈都震了。有大V總結(jié)道:AI編程大戰(zhàn),已經(jīng)達(dá)到了新的高峰。泄露信息顯示,DeepSeek V4在SWE-bench Verified上取得了驚人的83.7%,超過了Claude Opus 4.5(80.9%)和GPT-5.2(80%)。可以說(shuō),100萬(wàn)+上下文長(zhǎng)度+Engram記憶機(jī)制=真正的全倉(cāng)庫(kù)級(jí)推理能力。
還有網(wǎng)友綜合了全網(wǎng)DeepSeek V4消息,不僅在Humaneval、SWE_bench、上下文和成本上刷新成績(jī),而且發(fā)布時(shí)間預(yù)計(jì)在春節(jié),也就是明天!成本:據(jù)稱比OpenAI便宜20到40倍,預(yù)計(jì)發(fā)布時(shí)間:2月17日。如果是真的,DeepSeek將又一次改變游戲規(guī)則。總之,DeepSeek V4的發(fā)布時(shí)間,很可能是周一。據(jù)說(shuō),這是首個(gè)不落后于閉源頂尖模型,甚至能與之匹敵甚至超越的模型。
不過,這幾張流傳出來(lái)的基準(zhǔn)測(cè)試,很快被懷疑是假的。比如在官方評(píng)分系統(tǒng)下,不可能有模型達(dá)到99.4%的分?jǐn)?shù)。最高分只能是99.2%或 100%。另Epoch AI也確認(rèn),F(xiàn)rontierMath的數(shù)據(jù)是偽造的,因?yàn)橹挥兴麄兒蚈penAI有權(quán)對(duì)該數(shù)據(jù)集進(jìn)行評(píng)估。至少有兩個(gè)基準(zhǔn)測(cè)試被打假,證明這些圖可信度確實(shí)不高。有趣的是,即便是假的,這也說(shuō)明DeepSeek的確深得人心,網(wǎng)上的夸大其詞的泄露就是DeepSeek成功最大的標(biāo)志。
還有網(wǎng)友綜合了全網(wǎng)DeepSeek V4消息,不僅在Humaneval、SWE_bench、上下文和成本上刷新成績(jī),而且發(fā)布時(shí)間預(yù)計(jì)在春節(jié),也就是明天!成本:據(jù)稱比OpenAI便宜20到40倍,預(yù)計(jì)發(fā)布時(shí)間:2月17日。如果是真的,DeepSeek將又一次改變游戲規(guī)則。總之,DeepSeek V4的發(fā)布時(shí)間,很可能是周一。據(jù)說(shuō),這是首個(gè)不落后于閉源頂尖模型,甚至能與之匹敵甚至超越的模型。
不過,這幾張流傳出來(lái)的基準(zhǔn)測(cè)試,很快被懷疑是假的。比如在官方評(píng)分系統(tǒng)下,不可能有模型達(dá)到99.4%的分?jǐn)?shù)。最高分只能是99.2%或 100%。另Epoch AI也確認(rèn),F(xiàn)rontierMath的數(shù)據(jù)是偽造的,因?yàn)橹挥兴麄兒蚈penAI有權(quán)對(duì)該數(shù)據(jù)集進(jìn)行評(píng)估。至少有兩個(gè)基準(zhǔn)測(cè)試被打假,證明這些圖可信度確實(shí)不高。有趣的是,即便是假的,這也說(shuō)明DeepSeek的確深得人心,網(wǎng)上的夸大其詞的泄露就是DeepSeek成功最大的標(biāo)志。