本文字數:1213,閱讀時長大約3分鐘
作者 | 第一財經 劉曉潔
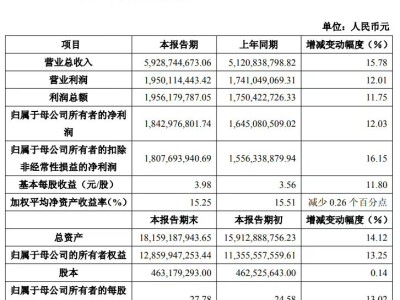
在業界對新一代旗艦模型DeepSeek V4的翹首期盼中,DeepSeek團隊卻悄然放出了一篇新的學術論文。
這篇論文由DeepSeek聯合北大、清華共同撰寫,將研究方向投向了決定大模型實際應用落地的關鍵一環——推理速度,為日益復雜的AI智能體,提供一套高效的底層系統解決方案。
論文在引言部分提到,大模型正從單輪對話機器人和獨立推理模型,快速演進為智能體系統 ——能夠自主規劃、調用工具,并通過多輪交互解決實際任務。這種應用范式的轉變,推動大模型推理工作負載發生重大變革:從傳統的人類-大模型交互,轉向人類-大模型-環境交互,交互輪次可達數十甚至數百輪。
上下文會跨輪次累積,最終長度可能達到極值。此時模型不需要大量計算,反而需要頻繁從硬盤讀取歷史上下文的 KV-Cache;現有系統中,只有負責預處理的引擎會讀取KV-Cache,它的網卡帶寬被占滿,而負責生成內容的解碼引擎,網卡帶寬基本閑置,導致整個系統速度被卡脖子。
這一論文成果延續了DeepSeek一貫的風格,在工程化層面將性能優化推向極致。有從業者認為,DeepSeek做這類優化屬于缺顯卡的無奈之舉,屬于“臟活兒累活兒”,大家更期待團隊在模型上做創新。
但也有人認為,即便有足夠顯卡,這類優化在降低成本、降低token費用方面也很有價值,因為只有足夠便宜,AI才能走向大規模使用。
相比這篇“務實”的論文,外界顯然更關注DeepSeek新一代旗艦模型的真面目。關于DeepSeek V4的發布時間,市場傳聞已幾經更迭。從最初傳聞的2月春節前后,到外媒最新報道的“最快下周”,再到業內人士預測的3月前后,傳聞鏈條愈發撲朔迷離。
就在近日,外網有網友爆料稱,DeepSeek 正在測試 V4 Lite 模型,代號為“Sealion-lite”,上下文窗口為 100萬tokens,并原生支持多模態推理。也有消息提及,DeepSeek已在近期將重大更新版本V4向華為等國內廠商提供提前訪問權,以支持其優化處理器軟件,確保模型在硬件上高效運行。然而,英偉達等廠商尚未獲得類似權限。
面對傳聞,DeepSeek依舊保持其一貫的沉默,目前并未進行任何回應。但市場已進入“嚴陣以待”狀態,部分投資機構擔憂,新一代模型的發布會如同去年的版本發布時那樣,引發市場的劇烈震蕩。