人的智能能力主要由推理能力和長期記憶能力構成。近年來,大模型的推理能力一直處于快速發展過程,但大模型的長期記憶能力一直受限于上下文長度,無法取得突破。在歷史上,曾經有多種路線進行嘗試,但都無法突破擴展性(Scalability)、精度(Precision)和效率(Efficiency)的不可能三角。近期,《MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens》的工作進入我們的視野。
文章中提出了一種新的記憶架構,MSA(Memory Sparse Attention),通過記憶稀疏注意力機制、實現超長上下文外推的文檔級旋轉位置編碼(document-wise RoPE)、KV 緩存壓縮與內存并行,以及支持復雜推理的記憶交錯(Memory Interleave)機制,實現了 100M 長度的大模型長時記憶框架,在主流的長文本問答、大海撈針等評測上,取得了業界領先的結果。并且,當長度由 16K 增加到 100M 時,模型的得分只下降了 9%,體現了非常強的擴展能力。
這個方法可以看作是大模型的一個記憶插件,為我們解決長期記憶問題提供了一個新的思路和方向。在今天 OpenClaw 引發的 Agent 爆發時代到來之際,這篇文章有望成為開啟 “記憶即服務”(Memory-as-a-Service)新紀元的里程碑。

GitHub 鏈接:https://github.com/EverMind-AI/MSA
論文鏈接:https://zenodo.org/records/19103670
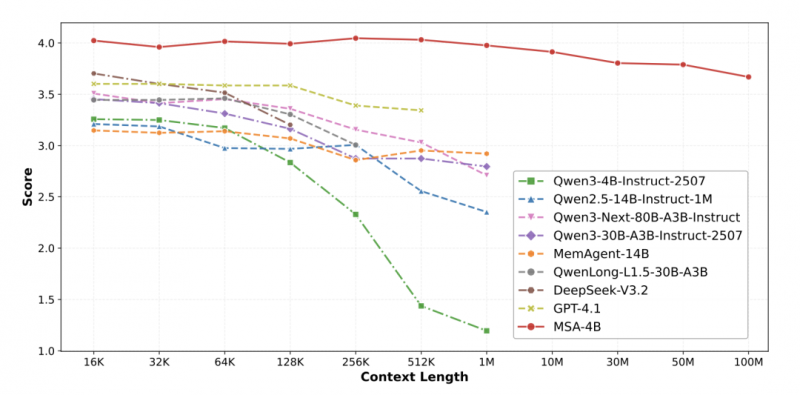
圖 1 MSA-4B 的長文本問答得分隨上下文長度衰減顯著優越(論文原圖)
1. LLM 長時記憶的 “不可能三角”
近年來,大型語言模型(LLM)的能力邊界不斷拓寬,但在模擬人生(Life Long)級別的長時、細粒度記憶方面,始終面臨著一道難以逾越的鴻溝。無論是需要通讀并理解長篇小說的文學分析,還是要求在多輪對話中保持人格一致性的數字孿生,抑或是需要追溯漫長歷史記錄的 Agent 系統,都對模型的有效上下文長度提出了近乎苛刻的要求。然而,主流 LLM 受限于全注意力機制(Full Attention)的二次方復雜度,其有效上下文窗口長期被限制在百萬(1M)Token 左右,與人類一生約數億 Token 的記憶容量相去甚遠。
為了突破這一瓶頸,學界和業界探索了三條主要的技術路線,但每條路線都在試圖解決問題的同時,陷入了新的困境,形成了一個難以調和的 “不可能三角”:
1. 參數化記憶(Parameter-Based Memory):通過持續訓練或微調將知識 “燒錄” 進模型參數。此方法精度高,但擴展性差,更新成本高昂且易發生災難性遺忘。
2. 外部存儲記憶(External Storage-Based Memory):以檢索增強生成(RAG)為代表,將記憶外置于向量數據庫。此方法擴展性好,但其 “檢索 - 生成” 兩階段分離的非端到端特性,導致檢索精度成為性能瓶頸,難以進行深度語義對齊。
3. 潛狀態記憶(Latent State-Based Memory):利用模型內部的隱藏狀態(如 KV 緩存)作為工作記憶。此方法語義保真度高,但面臨著效率與容量的直接沖突。基于 KV 緩存局部保留的方法(如利用 Attention Sinks 機制的 StreamingLLM)精度高但擴展性受限;而基于線性注意力的方法(如 RWKV, DeltaNet)雖然實現了線性復雜度,卻因有損壓縮而在超長上下文中精度嚴重下降。
正是在這一背景下,《MSA》一文提出了一個極具雄心的目標:設計一個端到端可訓練的、能以線性復雜度擴展至億級 Token、同時保持高精度的潛狀態記憶框架。MSA 的出現,旨在正面挑戰并打破上述 “不可能三角”,為 LLM 賦予真正意義上的 “終身記憶”。
2. MSA 架構深度剖析:四大創新支柱
MSA 的革命性并非源于單一技術的突破,而是一套環環相扣、系統性的架構創新。這套 “創新棧” 協同工作,共同構成了其高性能的基石。
2.1 核心基石:記憶稀疏注意力 (Memory Sparse Attention)
MSA 的核心思想是在 Transformer 的注意力層引入一種可微分的、基于內容的稀疏化機制。它不再讓模型在推理時關注所有歷史記憶,而是設計了一個高效的 “路由”(Routing)模塊,動態選擇最相關的記憶子集參與計算。
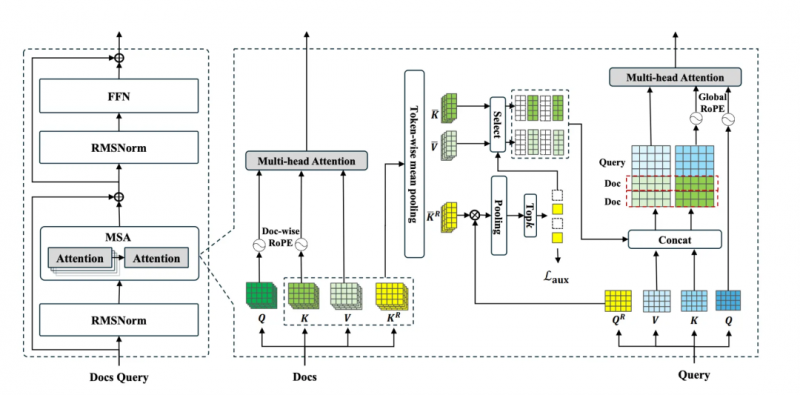
圖 2:記憶稀疏注意力架構 Memory Sparse Attention layer(論文原圖 )
這張圖是 MSA 技術實現的核心,展示了一個高度優化的 Transformer 層如何將海量外部記憶(Docs)與當前查詢(Query)高效融合。其流程可分解為左右兩個協同工作的模塊。
左側是標準的 Transformer 外殼。 整體上,MSA 層被包裹在一個標準的 Pre-Norm Transformer 模塊中。它取代了傳統的自注意力(Self-Attention)層,其輸出與輸入通過殘差連接(Residual Connection,圖中的⊕符號)相加,隨后經過 RMSNorm 歸一化和 FFN(前饋網絡)層處理。這一設計確保了 MSA 可以作為即插即用的模塊,無縫集成到現有的大模型架構中,無需對整體架構進行顛覆性改造。
右側是 MSA 的 "雙重路由" 稀疏注意力機制。 這是創新的核心,通過一個精巧的 "雙重路由" 機制,實現了從海量文檔中 "優中選優" 的過程,避免了對所有記憶進行暴力全量計算。
首先是輸入與投影階段:模型接收外部知識庫(Docs)和當前上下文的查詢(Query)。知識庫被投影成四份獨立的表征:Q(查詢)、K(鍵)、V(值),以及一個專門用于路由的鍵 K^R(Routing Key)。
其次是第一重路由(Topic-level,主題級篩選):模型首先對整個知識庫進行粗粒度的 "主題篩選"。它通過一個注意力機制(圖中的 Multi-head Attention)和 Token-wise mean pooling 操作,計算出當前 Query 與所有文檔 "主題"(由 K^R 代表)的關聯度,輸出一個主題概率分布,決定哪些文檔在宏觀上與當前查詢最相關。同時,輔助損失 L_aux 在此處被計算,以確保路由的稀疏性和有效性,防止所有查詢都涌向少數幾個熱門文檔,保證記憶的均衡利用。
然后是第二重路由(Token-level,詞元級精篩):在第一步鎖定的相關文檔內部,模型進行更精細的 "內容篩選"。通過 Pooling 和 Top-k 操作,在詞元級別上計算查詢與具體內容塊的相似度,從相關文檔中進一步挑選出最關鍵的句子或段落(圖中綠色高亮的小方塊)。
最后是最終注意力計算階段:經過 "雙重路由" 后,只有被選中的、最精華的 K 和 V 向量才會被加載到注意力計算中。這些經過稀疏化處理的記憶 K/V,與原始的 Query 的 K/V 進行拼接(Concat),共同進入最終的 Multi-head Attention 層,生成最終輸出。
這一機制的獨創性在于,它將 RAG 系統中的 "檢索" 步驟,內化為了一個可端到端訓練的神經網絡模塊。與依賴外部、固定的相似性度量(如向量余弦距離)的 RAG 不同,MSA 的路由器是在訓練過程中與生成任務共同優化的(通過一個輔助的對比學習損失 L_aux),這意味著它能學會一種更符合模型內部 "世界觀" 的、與最終任務目標更對齊的檢索策略。這從根本上解決了 RAG"檢索" 與 "生成" 目標不一致的核心痛點,是其實現高精度的關鍵。
2.2 擴展性關鍵:文檔級旋轉位置編碼 (document-wise RoPE)
要實現從較短的訓練文本(如 64k)到億級推理文本的成功外推,一個核心挑戰是如何處理位置信息。如果采用傳統的全局位置編碼,當推理時的文檔數量遠超訓練時,位置索引會發生劇烈偏移,導致模型 “水土不服”,性能急劇下降。
MSA 為此提出了一個簡潔而高效的解決方案:為每個獨立的文檔(或記憶單元)分配一套獨立的旋轉位置編碼(RoPE)。這意味著,無論記憶庫中有多少文檔,模型在 “閱讀” 每個文檔時,其內部的 “坐標系” 都是從 0 開始的、穩定不變的。這種設計將文檔的內部相對位置與其在全局記憶中的絕對位置解耦,使得模型在訓練時學到的位置感知能力,可以無損地泛化到包含海量文檔的推理場景中。這正是 MSA 能夠實現驚人外推能力(Extrapolation)的理論基礎。
2.3 工程化落地:KV 緩存壓縮與內存并行 (KV Cache Compression & Memory Parallel)
理論上的可行性必須通過工程實現才能轉化為現實。在億級 Token 的尺度下,即便經過壓縮,KV 緩存的存儲需求也高達上百 GB,遠超單個 GPU 節點的顯存容量。MSA 通過一套精巧的 “內存并行” 策略解決了這一物理瓶頸。
分層存儲(Tiered Storage):MSA 敏銳地觀察到,在路由階段,模型僅需要體積相對較小的路由鍵 KR 來進行快速匹配;而體積龐大的內容鍵值 K 和 V,只有在 Top-k 選擇完成后才需要。因此,它設計了一套分層存儲系統:
GPU 常駐路由鍵:將所有文檔的 KR 分布式地存儲在多張 GPU 的高速顯存中,確保低延遲的全局檢索。
CPU 卸載內容鍵值:將占據絕大部分空間的 K 和 V 矩陣存儲在大容量的 CPU 內存(DRAM)中。
異步調度(Asynchronous Fetching):當 GPU 完成路由計算、確定 Top-k 文檔后,系統再異步地從 CPU 內存中調取所需的內容 KV 到 GPU,用于最終的生成計算。
這種 “快查(GPU)慢取(CPU)” 的策略,優雅地將存儲瓶頸從有限的 GPU 顯存轉移到了海量的 CPU 內存,使得在標準硬件(如 2 張 A800 GPU)上運行億級 Token 的推理成為可能。這不僅是工程上的創舉,更是該技術能夠走向實際應用的前提。
2.4 復雜推理能力:記憶交錯 (Memory Interleave)
對于需要整合多個分散在不同文檔中的證據才能回答的復雜問題(即多跳推理),單次的 “檢索 - 生成” 循環往往力不從心。為此,MSA 引入了記憶交錯機制。
該機制允許模型進行多輪次的 “生成式檢索 → 上下文擴展” 循環。在第一輪,模型根據原始問題,首先生成它認為最相關的文檔 ID 序列;隨后,系統獲取這些文檔的原文,并將其追加到原始問題之后,形成一個新的、更豐富的 “中間問題”;在下一輪,模型基于這個新問題,再次生成新的文檔 ID…… 如此循環往復,直到模型認為積累的證據足夠充分,便停止生成文檔 ID,轉而生成最終答案。
這種迭代式的推理鏈,模擬了人類偵探辦案時 "發現線索 A → 順藤摸瓜找到線索 B → 整合 AB 形成完整證據鏈" 的思考過程。它賦予了 MSA 動態規劃其信息搜集路徑的能力,是其在多跳問答(Multi-hop QA)任務上表現出色的重要原因。
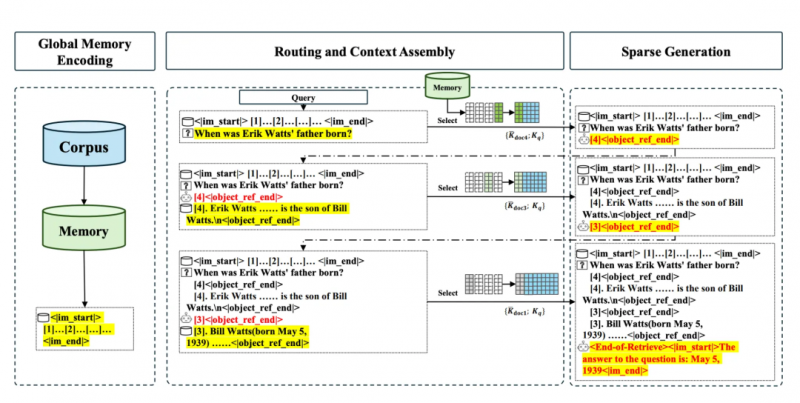
圖 3:三階段流程圖 — Three-Stage Inference Process with Memory Interleave(論文原圖)
這張圖以一個具體的多跳問答案例("埃里克?瓦茨的父親何時出生?")為例,完整展示了記憶交錯機制在推理時的三階段工作流程。
第一階段:全局記憶編碼(Global Memory Encoding,圖左)。 這是一個離線預處理步驟。整個知識語料庫(Corpus)被一次性編碼,生成一個龐大的 KV 緩存,即全局 "記憶"(Memory)。這個記憶庫通常存儲在成本更低的 CPU 內存或 SSD 中,等待被實時查詢調用。這一階段的計算成本是一次性的,與后續的推理次數無關。
第二階段:路由與上下文組裝(Routing and Context Assembly,圖中)。 這是推理的核心循環,圖中以三步迭代為例展示了完整的證據鏈構建過程。
在第 1 輪迭代中,用戶提出初始問題(埃里克?瓦茨的父親何時出生?)。模型使用這個問題作為 Query,通過 MSA 的路由機制,從全局 Memory 中檢索到第一個最相關的證據塊:Erik Watts ...... is the son of Bill Watts(埃里克?瓦茨是比爾?瓦茨的兒子)。此時上下文中只有 "誰是埃里克的父親" 這一信息,尚不足以直接回答問題,模型因此生成一個中間引用標記 [4],表示已定位到文檔 4,并將其內容納入上下文。
在第 2 輪迭代中,上下文已擴展,包含了第 1 輪獲取的證據。模型在內部生成一個新的、更具體的查詢需求(即 "比爾?瓦茨何時出生?"),并再次調用 MSA 路由機制,這次檢索到了包含比爾?瓦茨出生日期的證據塊:Bill Watts born May 5, 1939(比爾?瓦茨,生于 1939 年 5 月 5 日)。模型再次生成引用標記 [3],將文檔 3 的內容追加到上下文中。
第三階段:稀疏生成(Sparse Generation)。 當證據鏈完整后,上下文同時包含了 "埃里克的父親是比爾" 和 "比爾的生日是 1939 年 5 月 5 日" 兩條關鍵證據。模型在最后一次生成步驟中,輸出特殊標記 < End-of-Retrieve>,宣告證據搜集結束,隨后整合所有證據,生成最終的、高確定性的答案:The answer to the question is: May 5, 1939(答案是:1939 年 5 月 5 日)。
這張圖直觀地揭示了記憶交錯機制的本質:它將 "推理" 與 "檢索" 深度交織,使模型能夠像一位經驗豐富的研究員一樣,從一個模糊的初始問題出發,通過逐步發現、逐步聚焦的方式,最終鎖定精確答案。這種能力對于解決真實世界中那些答案分散在多個文檔中的復雜問題,具有不可替代的價值。
3. 實驗數據再解讀:MSA 的價值驗證
論文通過一系列詳盡的實驗,從多個維度驗證了 MSA 架構的有效性。我們將核心數據可視化并進行解讀。
3.1 驚人的擴展性與魯棒性
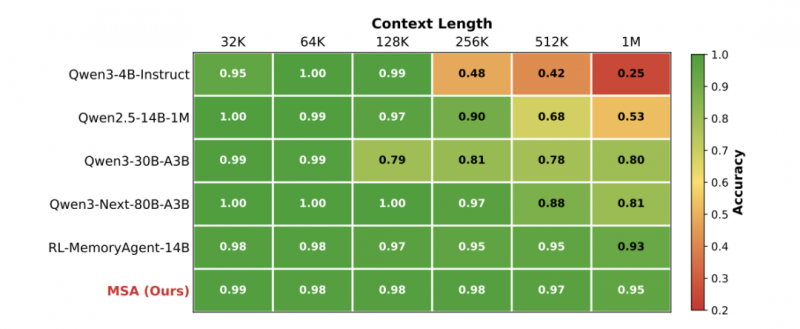
圖 4:在 “大海撈針”(NIAH)測試中,MSA 在上下文從 32K 擴展至 1M 時,準確率僅從 99% 下降至 95%,表現出極強的穩定性。相比之下,其他長上下文模型則在256K后顯著衰減(論文原圖)。
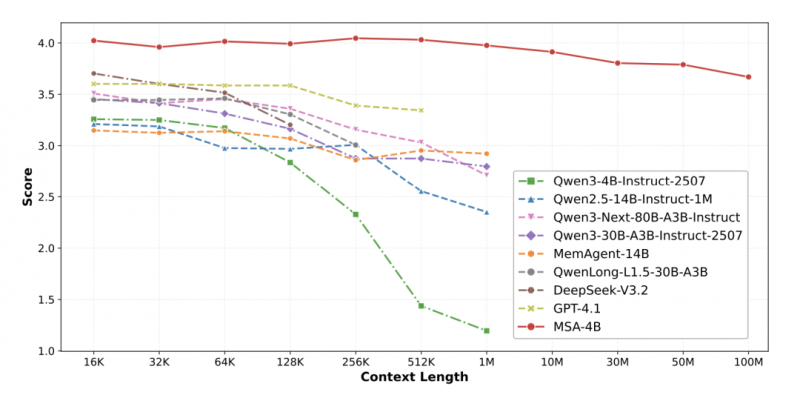
圖 5:論文原圖,在更極限的 MS MARCO 問答測試中,將記憶規模從 16K 擴展至 100M(跨越 4 個數量級),MSA 的性能評分僅從 4.023 下降至 3.669,衰減率不足 9%。這直觀地證明了其架構在抵抗大規模無關信息(噪聲)干擾方面的卓越魯棒性。
3.2 端到端優化的威力
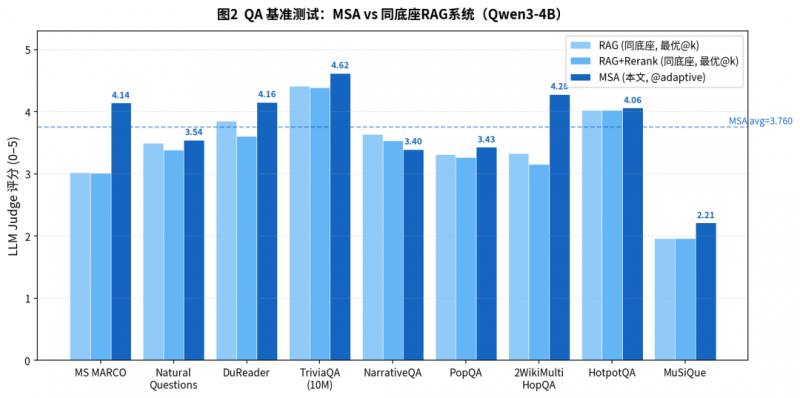
圖 6:在 9 個 QA 基準測試的平均分上,4B 參數的 MSA 模型(平均分 3.760)顯著優于基于同樣 4B 底座構建的、包含重排器(Reranker)的復雜 RAG 系統。甚至在多個數據集上,其表現超過了由 SOTA 的 KaLMv2 檢索器和 235B 參數的 Qwen3 巨無霸模型組成的頂級 RAG 系統。這充分證明了 MSA 端到端優化帶來的高精度優勢。
3.3 各組件的不可或缺性
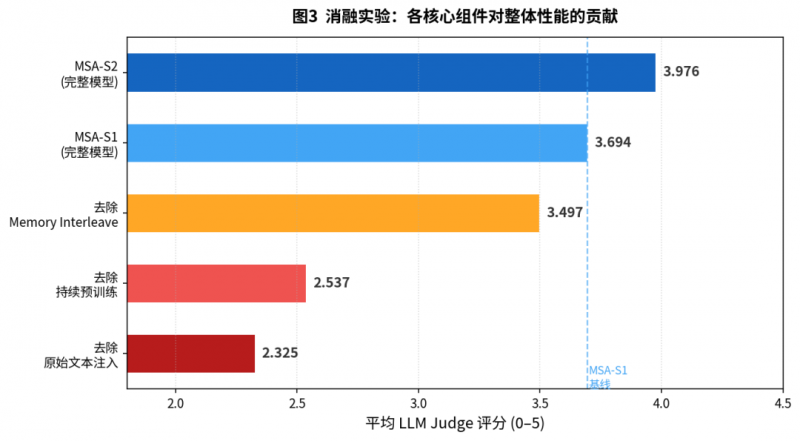
圖 7:消融實驗清晰地量化了每個創新點的貢獻。與基線模型 MSA-S1 相比,移除 “記憶交錯” 機制導致在多跳問答任務上性能大幅下降;移除 “持續預訓練” 中的輔助路由監督,則讓模型幾乎喪失了有效的檢索能力;而移除 “原始文本注入” 則造成最嚴重的性能滑坡,說明最終的精確回答仍需依賴原始文本的細節。這證明了 MSA 是一個設計精巧、各部分缺一不可的有機整體。
4. 總結:MSA 的獨創性與核心價值
綜合上述分析,我們可以總結出 MSA 論文的核心獨創性與價值點:

總而言之,MSA 的真正價值,并不僅僅是發布了一個性能強大的長上下文模型,而是為 AI 記憶領域提供了一套全新的、被完整驗證過的、兼具擴展性、精度與效率的技術基礎設施。 它證明了,我們不必在 RAG 的 “低精度” 和全注意力的 “高成本” 之間做出痛苦的妥協。通過將稀疏化思想與神經網絡的端到端學習能力巧妙結合,構建一個獨立的、可擴展的、與 LLM 兼容的 “記憶層” 是完全可行的。
這為未來 AI 生態的發展描繪了一幅激動人心的藍圖:記憶可以作為一種獨立的、可插拔的服務,與各種推理核心(LLM)自由組合,用戶的數據和 “記憶資產” 不再被鎖定在任何單一的模型或廠商中。從這個角度看,MSA 不僅是一篇優秀的學術論文,更可能是一個開啟 “記憶即服務”(Memory-as-a-Service)新紀元的里程碑。
5. 背景信息:EverMind 與盛大集團的 “發現式 AI” 愿景
為完整理解 MSA 研究背后的驅動力,有必要將其置于出品方 EverMind 及其母公司盛大集團(Shanda Group)的宏觀戰略背景下進行審視。EverMind 是盛大集團創始人陳天橋在 AI 領域深度布局、長期孵化的核心團隊之一,使命是攻克 AI 的長期記憶難題,走向AI的自我演化(Self Evolving)。
根據近期 Bloomberg 與鈦媒體 對陳天橋的專訪,盛大集團的 AI 戰略并非聚焦于當前主流的 “生成式 AI”,而是旨在構建一個更具開創性的 “發現式 AI(Discoverative AI)” 生態。其終極目標是讓 AI 輔助人類發現新知識、解決如疾病、能源等根本性問題,而非僅僅模仿和重組已有信息。在這一宏大愿景中,兩大技術基石被置于核心地位:
MiroMind:專注于推理(Reasoning)。該團隊致力于通過可驗證推理(Verifiable reasoning)等路徑,讓模型學會像科學家一樣主動向外部世界求證、修正假設,從而實現真正的推理可靠性與洞察發現。
EverMind:專注于記憶(Memory)。該團隊的使命是為 AI 打造一個可無限擴展、高保真、且獨立于任何特定模型的長期記憶系統。只有當 AI 擁有了穩定可靠的記憶底座,才能在其上進行有效的、跨越時空的復雜推理與知識創造,走向AI的自我演化(Self Evolving)。
因此,EverMind 與 MiroMind 共同構成了盛大集團‘發現式 AI’藍圖的核心驅動力,分別對應著 “記憶” 與 “推理” 這兩大認知科學的核心支柱。本文所介紹的 MSA 架構,正是 EverMind 團隊踐行‘記憶即服務’理念的核心技術成果。其底層設計與技術路線,不僅是對現有長文本瓶頸的突破,更深刻印證了盛大集團在構建獨立、自主、可控 AI 基礎設施上的長期投入與堅定決心。