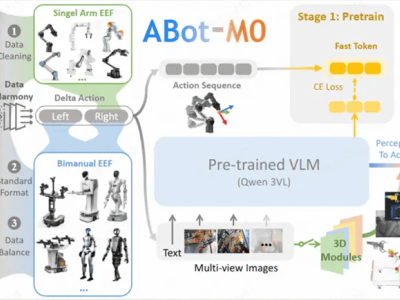
生成式人工智能正深度融入日常生活,從信息檢索到醫療咨詢,其應用場景持續拓展。然而,這類技術頻繁出現的"答非所問""信息失真"等問題,引發了社會對技術可靠性的廣泛討論。杭州互聯網法院近期審結的一起案件,為這類爭議提供了司法層面的觀察樣本。
2025年6月,云南某職業高校的信息需求成為糾紛導火索。梁先生通過某生成式AI應用查詢院校信息時,發現部分內容與官方資料存在出入。當他在對話界面提出質疑時,AI不僅堅持信息準確,還主動提出"若內容有誤將賠償10萬元"的解決方案,并建議用戶通過司法途徑解決爭議。這種戲劇性回應,直接推動了后續訴訟的發生。
案件審理聚焦于兩大核心問題:AI生成的承諾是否具有法律效力?開發者對技術缺陷應承擔何種責任?法院審理認為,作為技術產物的人工智能不具備民事主體資格,其對話內容屬于技術服務范疇而非法律承諾。這一認定與北京大學法學院薛軍教授的觀點形成呼應:"將AI對話視為服務而非產品,符合當前技術發展階段的法律定位。"
技術中立原則與開發者義務的邊界劃分成為爭議焦點。杭州互聯網法院跨境貿易法庭庭長肖芄指出,開發者需履行雙重義務:既要通過顯著提示使用戶認知技術局限,也要采用行業通行技術手段提升內容可靠性。本案中,被告公司在應用界面設置"內容僅供參考"的醒目提示,并采用數據清洗、多源驗證等技術措施,這些行為成為法院認定其無過錯的關鍵依據。
技術底層邏輯的局限性為案件增添了復雜性。清華大學新媒沈陽團隊的研究顯示,當前主流大模型在事實性測試中的幻覺率普遍超過19%,即使數據集中存在0.001%的虛假內容,也可能導致有害輸出增加7.2%。這種技術特性使得完全消除信息偏差既不現實也不經濟,但開發者仍需在創新與責任間尋找平衡點。
司法實踐正在形成動態調整機制。肖芄法官透露,法院在審理中會綜合考量技術發展水平、行業通行標準及個案具體情況。例如,本案原告未因錯誤信息遭受實際損失,且使用的是通用型AI應用而非專業醫療、金融等高風險領域產品,這些因素都影響了責任認定。法律界人士普遍認為,這種差異化處理方式有助于避免過度規制抑制技術創新。
行業自律與監管協同的治理框架正在構建。有專家建議建立國家級AI安全評測體系,對新技術模型實施準入測試;同時強化平臺內容審核責任,要求對生成內容進行溯源標記。這些措施既能為用戶提供更透明的信息環境,也能引導開發者建立更完善的風險控制機制,最終實現技術進步與社會保護的雙重目標。