在近日舉辦的AIFUT大會上,智譜CEO張鵬透露,國產(chǎn)大模型與全球頂尖水平仍存在半年至一年的差距。"過去積累的技術(shù)債務(wù)較多,需要加速追趕。"他坦言。這一觀點與零一萬物CEO李開復(fù)的判斷不謀而合,后者認(rèn)為中美頂尖大模型的差距在6至9個月之間。
盡管存在差距,中國AI大模型的市場表現(xiàn)卻格外亮眼。OpenRouter最新數(shù)據(jù)顯示,2026年3月第三周至第四周,中國大模型周調(diào)用量達(dá)9.857萬億Token,環(huán)比激增33.94%,連續(xù)四周超越美國同期3.007萬億Token的調(diào)用量,且差距持續(xù)擴大。美國市場同期增長率僅為1.79%,形成鮮明對比。
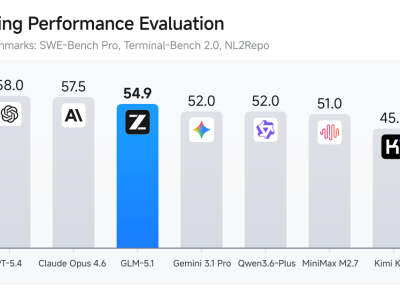
大會焦點之一是智譜發(fā)布的GLM-5.1模型。該模型在長程任務(wù)處理上取得重大突破,可連續(xù)自主工作8小時,在SWE-bench Pro基準(zhǔn)測試中超越Claude Opus 4.6,創(chuàng)下全球最佳成績。張鵬將AI發(fā)展劃分為三個階段:從GPT-3的知識壓縮到DeepSeek的資源優(yōu)化,最終邁向推理與自學(xué)習(xí)階段。他強調(diào),智譜正通過多能力平衡發(fā)展策略,解決現(xiàn)實世界的復(fù)雜規(guī)劃問題。
在商業(yè)策略上,智譜選擇逆勢提價。GLM-5.1發(fā)布后,其API價格上調(diào)10%,編碼場景定價已接近Anthropic旗下Claude Sonnet4.6水平。這一舉措在行業(yè)普遍降價爭奪市場份額的背景下顯得尤為突出。張鵬解釋稱,這反映了中國大模型國際地位的提升,以及市場對高質(zhì)量模型的需求增長。
智譜的創(chuàng)新實驗室(Lab業(yè)務(wù))也引發(fā)關(guān)注。該實驗室專注于前沿技術(shù)探索,包括神經(jīng)網(wǎng)絡(luò)優(yōu)化、軟硬件接口打通等方向。張鵬表示,實驗室的中短期路徑明確,旨在保持公司技術(shù)多樣性和創(chuàng)新活力,推動核心能力在應(yīng)用領(lǐng)域的落地。對于AI Agent的發(fā)展,他預(yù)測2026年將成為真正的"應(yīng)用元年",其判斷基于模型能力、工程架構(gòu)與系統(tǒng)工具鏈的協(xié)同進化,而非單純的技術(shù)突破。