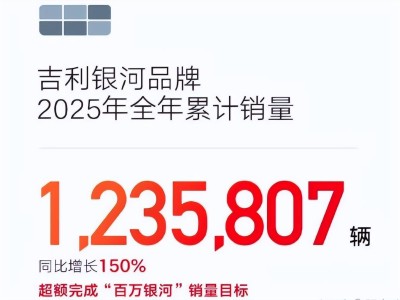
阿里國際數(shù)字商業(yè)團隊在混合專家(MoE)模型領域取得重要進展,推出基于創(chuàng)新訓練范式的輕量化模型Marco-Mini-Instruct。該模型通過獨特的架構轉換技術,在保持極低激活參數(shù)量(0.86B)的同時,實現(xiàn)了超越傳統(tǒng)4B級Dense模型的性能表現(xiàn),為MoE架構的落地應用開辟了新路徑。
模型核心突破在于采用Upcycling技術完成架構升級。研發(fā)團隊以Qwen3-0.6B-Base模型為基礎,通過模塊拆分與專家化改造,將原始Dense模型轉化為MoE架構。具體實現(xiàn)中,研究人員將部分網絡層復制為多個專家模塊,并引入動態(tài)路由機制分配計算任務。訓練過程中采用的Drop-Upcycling策略通過隨機丟棄專家路徑的方式增強模型魯棒性,配合細粒度子矩陣切分技術,最終實現(xiàn)架構平滑轉換。
在硬件適配性方面,該模型展現(xiàn)出顯著優(yōu)勢。官方測試數(shù)據(jù)顯示,采用8bit量化并配置4條DDR4 2400內存的條件下,模型推理速度可達30token/s,可在普通CPU設備上流暢運行。這一特性極大降低了本地部署門檻,使MoE架構首次具備消費級設備運行能力。模型配置中雖將最大位置編碼擴展至32K,但實際訓練采用8192token上下文窗口,平衡了性能與資源消耗。
后訓練階段采用級聯(lián)式知識蒸餾策略。團隊首先使用Qwen3-30B模型進行基礎能力對齊,隨后引入更強大的Qwen3-Next-80B模型進行多維度優(yōu)化。蒸餾數(shù)據(jù)涵蓋指令理解、邏輯推理、安全對齊等20余個能力維度,確保模型在保持輕量化的同時具備綜合智能表現(xiàn)。實際測試表明,該模型在多數(shù)基準測試中超越Qwen3-4B等傳統(tǒng)Dense模型,驗證了MoE架構在參數(shù)效率方面的優(yōu)勢。
開發(fā)成本的控制成為該成果的另一亮點。完整訓練流程包含監(jiān)督微調(SFT)和知識蒸餾兩個階段,分別需要64塊GPU運行24小時和110小時。這種可量化的訓練成本,配合清晰的架構轉換方法論,為中小研發(fā)團隊提供了可復現(xiàn)的技術路徑。行業(yè)分析師指出,這種"小模型大改造"的模式,或將改變當前大模型訓練的資源密集型發(fā)展路徑。
技術文檔顯示,模型激活參數(shù)僅占總參數(shù)的5%,這種設計使其在邊緣計算場景具有獨特優(yōu)勢。研發(fā)團隊特別優(yōu)化了專家模塊間的通信效率,確保在低算力設備上仍能維持高效推理。實際部署測試表明,模型在智能客服、移動端AI助手等場景中,響應速度與效果均達到實用標準,為MoE技術商業(yè)化落地提供了重要參考。