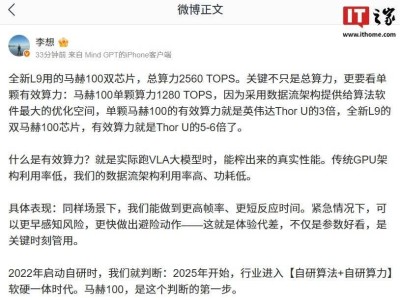
云知聲近日正式推出“山海·知音”大模型2.0版本,標志著其“一基兩翼”技術戰略進入關鍵落地階段。該版本依托“山海·Atlas”多模態基座架構,在語音交互領域實現三大突破性升級,通過ASR、TTS與全雙工交互能力的協同進化,重新定義了智能語音技術的實用價值邊界。
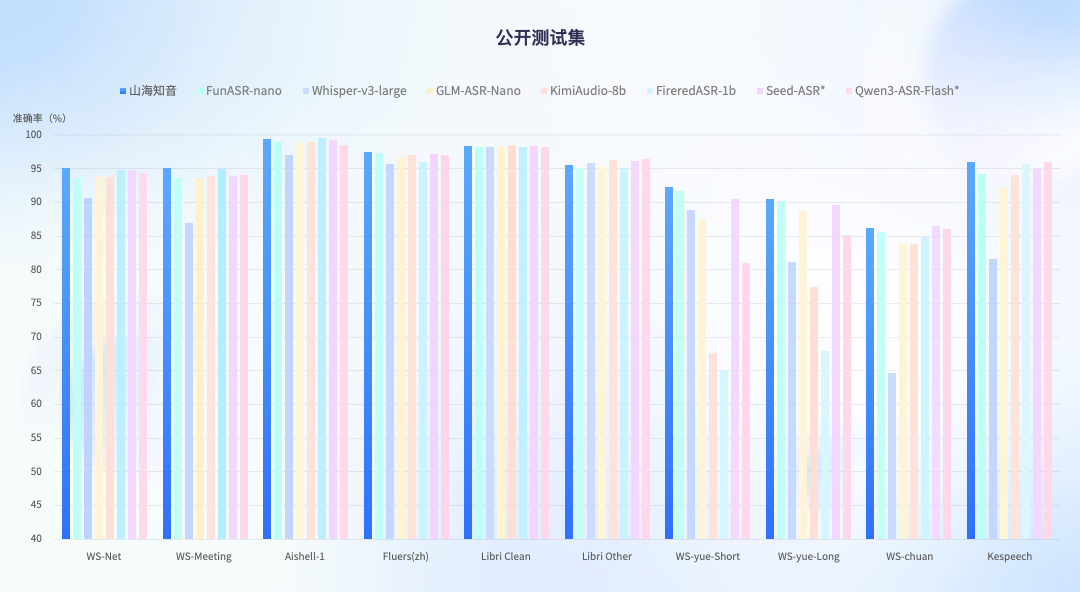
在語音識別維度,新模型通過架構革新實現場景覆蓋的質的飛躍。測試數據顯示,其ASR模塊在公開數據集與全場景自有測試中均達到行業頂尖水平,尤其在復雜聲學環境下表現突出:面對工地噪音、交通喧嘩等極端場景,識別準確率較主流模型提升2.5%-3.6%,方言混合語音識別準確率突破90%大關。這種突破源于對聲學建模與語言模型的深度耦合優化,使系統能動態適應不同口音特征與背景噪聲模式。
語音合成領域的技術創新同樣引人注目。全新TTS系統支持12種方言與10種外語的流暢輸出,通過聲紋克隆技術實現笑聲、呼吸聲等非語言特征的精準復現。更值得關注的是其延遲控制技術:研發團隊摒棄傳統流匹配方案的分段處理模式,創新設計純因果注意力機制,配合神經聲碼器的聯合優化,將端到端語音生成延遲壓縮至90毫秒以內。這種突破使實時對話場景中的語音反饋更加自然,徹底解決了傳統方案中音質與延遲難以兼顧的痛點。
全雙工交互能力的升級則聚焦于對話連貫性。新系統通過端到端交互大腦架構,實現了語音理解、決策生成與狀態維護的同步進行。測試表明,在多輪對話、隨意打斷等復雜場景下,系統能保持上下文記憶的完整性,響應流暢度達到人類對話水平。這種能力突破為醫療問診、車載交互等需要即時響應的場景提供了技術支撐,使AI助手真正具備"邊聽邊想邊說"的類人交互特質。
支撐這些技術突破的"山海·Atlas"基座架構,通過多模態大模型與底層算力平臺的深度整合,構建起感知-認知-決策的完整技術鏈條。該架構將傳統語音處理模塊轉化為端到端大模型的有機組成部分,在保持專業領域精度的同時,實現了跨場景能力的平滑遷移。目前,基于該架構的"山海·知醫"醫療大模型已完成5.0版本迭代,與最新發布的語音交互系統形成技術協同效應。
從手術室的精準指令識別到鄉村診所的方言問診,從智能座艙的實時交互到適老化設備的語音陪伴,云知聲正通過技術普惠推動AI應用邊界的持續拓展。此次升級不僅解決了語音交互領域長期存在的場景適應性難題,更通過底層架構創新為垂直行業智能化提供了可復制的技術范式。當AI開始理解方言的韻律、捕捉對話的情感、把握打斷的時機,智能語音技術正從實驗室走向真實生活場景,成為真正懂人心的交互伙伴。