全球影視與創(chuàng)意內容生產領域迎來重大變革——可靈AI正式推出3.0系列模型,標志著AI技術深度融入專業(yè)影像創(chuàng)作流程。該系列包含可靈視頻3.0、可靈視頻3.0 Omni、可靈圖片3.0及可靈圖片3.0 Omni四大核心模型,覆蓋從前期分鏡設計到后期特效合成的全鏈條,目前已向黑金會員開放使用,預計將在短期內完成全面部署。
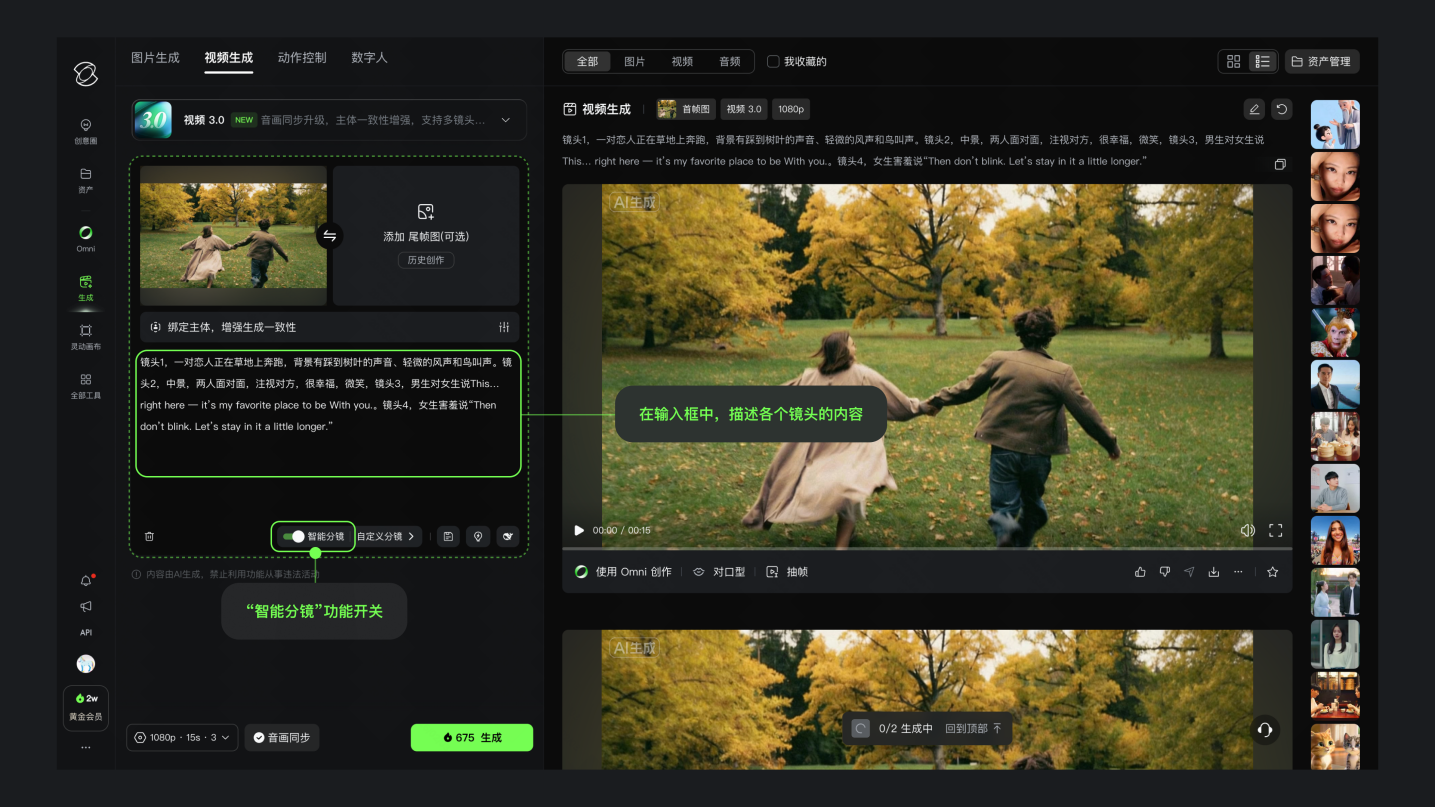
技術架構層面,3.0系列突破傳統(tǒng)模塊化設計,構建了全球首個多模態(tài)輸入輸出一體化模型體系。通過統(tǒng)一架構將理解、生成、編輯三大環(huán)節(jié)無縫銜接,創(chuàng)作者可同時使用文本、圖像、音頻及視頻作為輸入指令,直接獲得具備專業(yè)級質感的影像輸出。這種"端到端"的創(chuàng)作模式,徹底改變了以往需要切換多個工具、經(jīng)歷多輪修正的繁瑣流程。在穩(wěn)定性控制方面,模型通過整合視頻主體錨定、音色綁定及"圖生視頻+主體參考"專利技術,成功解決人物形象扭曲、動作斷層等行業(yè)痛點,確保復雜鏡頭切換中角色特征、品牌標識及文字信息的持續(xù)統(tǒng)一。
敘事能力實現(xiàn)質的飛躍是本次升級的顯著特征。視頻模型支持最長15秒的連續(xù)生成,內置智能分鏡系統(tǒng)可自動完成鏡頭調度與景別轉換。創(chuàng)作者通過簡單的參數(shù)調整,即可實現(xiàn)"正反打"對話、跨場景轉場等復雜敘事結構,鏡頭語言的表現(xiàn)力較前代提升40%以上。在音畫同步領域,模型突破多語言適配瓶頸,不僅支持中英日韓西等主流語言,還涵蓋粵語、川渝方言等20余種地方口音,人物口型匹配精度達到98.7%,情感表達自然度獲得專業(yè)影視從業(yè)者認可。
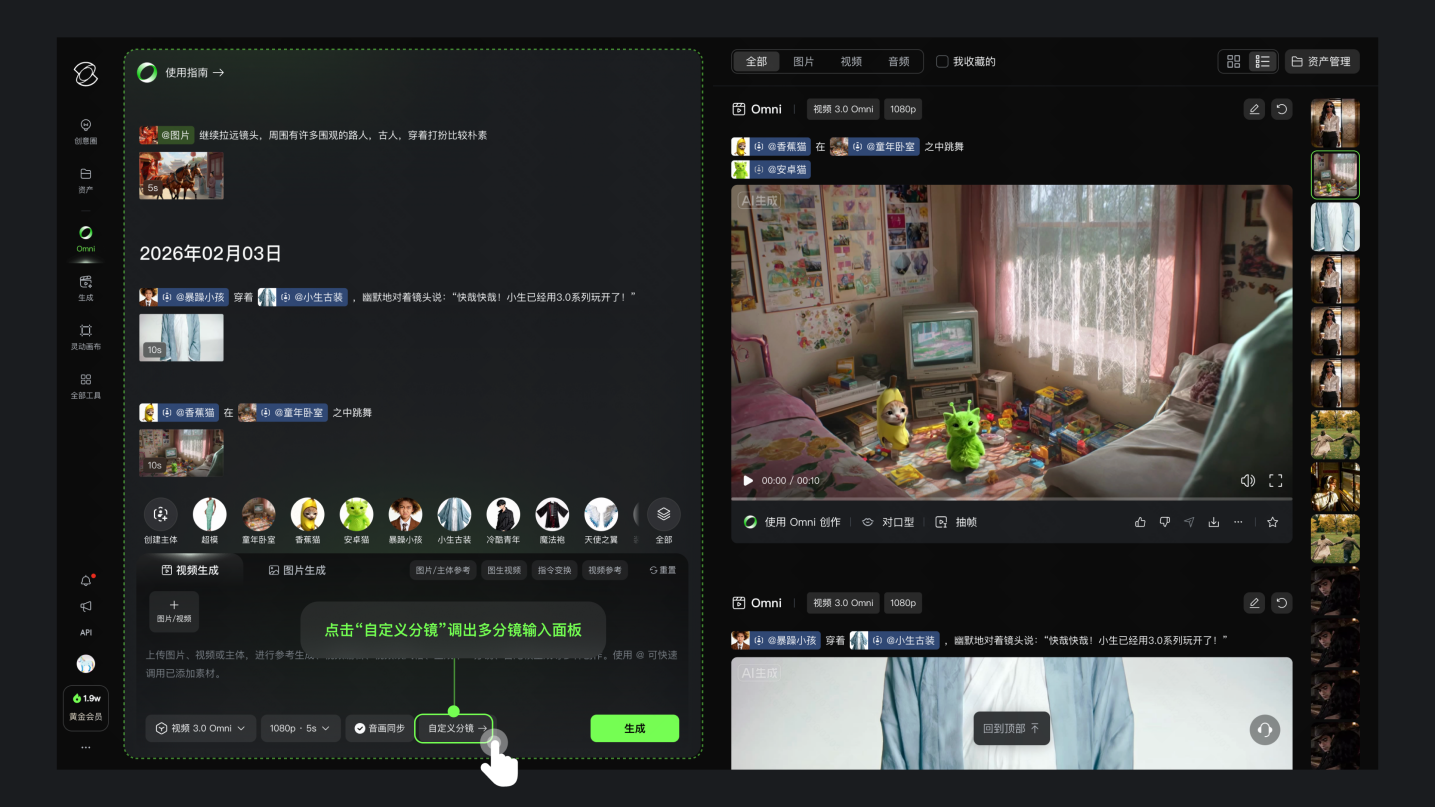
針對不同創(chuàng)作場景,Omni版本進一步強化定制化能力。通過特征解耦技術,創(chuàng)作者上傳的參考素材可被精準拆解為視覺特征與音色參數(shù),實現(xiàn)角色、道具在不同時空背景下的自由復用。測試數(shù)據(jù)顯示,該技術使數(shù)字資產復用效率提升65%,文字識別準確率突破99%,生成的系列組圖在光影邏輯、細節(jié)一致性方面達到電影級標準。圖片模型則聚焦靜態(tài)敘事,支持4K超高清輸出與分鏡圖生成,其構圖邏輯解析能力可自動匹配影視劇本的場景描述需求。
行業(yè)應用層面,3.0系列正在重塑內容生產格局。影視團隊利用智能分鏡功能,可在2小時內完成傳統(tǒng)需要3天制作的預演動畫;廣告公司通過主體錨定技術,使產品展示視頻的修改成本降低80%;游戲開發(fā)者則借助角色一致性控制,將數(shù)字資產開發(fā)周期從平均6周壓縮至2周。據(jù)最新運營數(shù)據(jù)顯示,該平臺已匯聚超6000萬創(chuàng)作者,累計生成作品突破6億件,服務企業(yè)客戶超3萬家,2025年度商業(yè)化收入預計達2.4億美元。
技術專家指出,可靈AI 3.0的突破性在于實現(xiàn)了從"工具屬性"到"創(chuàng)作伙伴"的范式轉變。通過構建可理解創(chuàng)作意圖的智能系統(tǒng),模型不僅能執(zhí)行具體指令,更能主動協(xié)調鏡頭關系、把控敘事節(jié)奏。這種進化使得單個創(chuàng)作者即可完成以往需要導演、攝影、剪輯等多工種協(xié)作的復雜項目,真正開啟了"人人都是導演"的創(chuàng)作新時代。