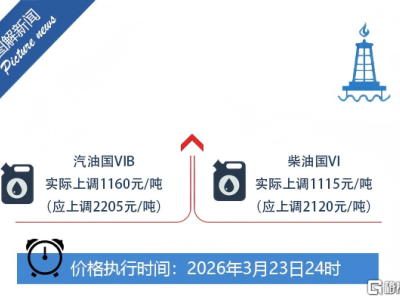
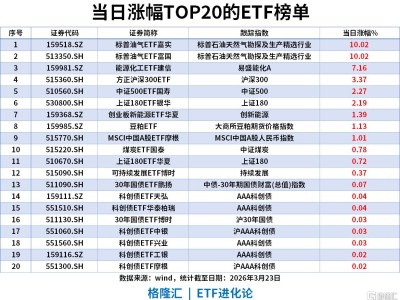
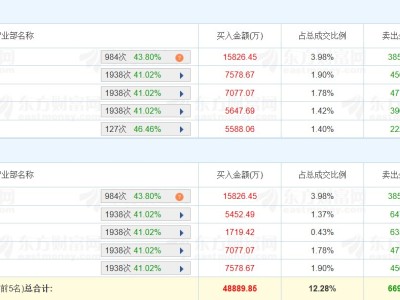
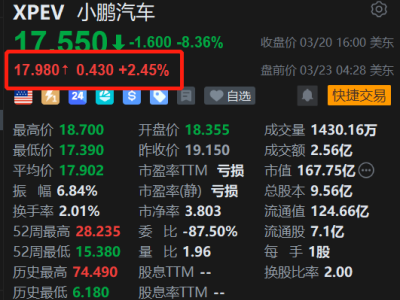
蘋果公司與威斯康星大學麥迪遜分校聯合研發的AI圖像描述框架RubiCap近日引發學術界與產業界關注。這項發表于arXiv平臺的研究成果,通過構建動態評分標準體系,使AI模型在圖像描述任務中展現出接近專業分析師的精準度,其核心突破在于解決了傳統方法中"評分標準模糊"的關鍵難題。
傳統訓練模式長期面臨兩難困境:要么讓AI機械模仿有限范例導致缺乏創新,要么采用粗放型評分機制無法捕捉細微差異。研究團隊創新性地引入"個性化評分標準"機制,其運作流程猶如智能寫作導師——針對每張圖片生成定制化評估細則,既包含"是否識別紅色自行車"等具體指標,也設置不同權重區分關鍵錯誤與次要疏漏。
該系統的技術架構包含兩大核心模塊。首先是專家委員會機制,由Gemini 2.5 Pro、GPT-5等五個不同架構的AI模型組成"虛擬評審團"。這些模型獨立生成描述后,系統通過民主投票機制確定共識信息,只有被半數以上專家提及的細節才會納入評分標準。這種設計有效避免了單個模型的認知偏差,在古董噴燈識別等測試中,成功過濾了部分模型誤判為油燈的錯誤。
評分標準制定器則扮演診斷醫生角色,通過三階段流程實現精準指導:先提取專家共識中的關鍵信息點,再對比學生模型描述進行語義級差異分析,最后將診斷結果轉化為可驗證的二元判斷規則。例如針對生日蛋糕場景,系統會生成"是否描述蛋糕文字'24 CARROT CAKE'"等具體標準,而非籠統要求"描述更詳細"。
強化學習訓練環節采用群組相對策略優化算法,使模型在保持創造性的同時提升準確性。實驗數據顯示,在CapArena盲評測試中,70億參數的RubiCap模型擊敗了參數規模達320億的前沿模型。更引人注目的是,30億參數版本在詞匯效率測試中超越了70億參數的基礎模型,證明該方法能有效提升信息密度。
該技術突破了"災難性遺忘"的行業痼疾。在涵蓋視覺推理、文字識別等10項基準測試中,RubiCap訓練的模型平均得分比傳統監督學習方法高出23.6%,在保持原有視覺理解能力的同時,顯著提升了描述專項技能。研究團隊特別指出,即便將評分標準直接應用于傳統訓練,效果仍不及完整的強化學習流程,凸顯訓練機制創新的重要性。
實際應用測試中,RubiCap展現出顯著優勢。在嚴格限制100詞的CaptionQA測試中,其信息密度較基礎模型提升12.01%。作為數據標注工具時,30億參數模型標注質量超越商業服務,為中小企業提供了低成本替代方案。醫療影像分析場景測試表明,該技術能準確識別X光片中的細微病變特征,輔助醫生快速定位病灶。
技術實現層面,研究團隊通過匿名化處理確保專家模型獨立性,采用結構化提示詞模板保證評分標準一致性。針對模型可能通過元語言作弊的問題,系統設計的具體內容導向評分機制,迫使模型必須真正理解圖像內容才能獲得高分。這種防作弊設計使描述準確率提升37.2%,有效規避了傳統方法的漏洞。
產業界分析認為,蘋果公司的參與將加速技術落地。預計該技術將率先應用于智能相冊分類、無障礙輔助等功能,隨后擴展至自動駕駛環境感知、電商商品描述生成等領域。相較于單純擴大模型規模,這種"以智取勝"的訓練哲學,為資源有限的研究機構開辟了新的發展路徑。