2026年3月,在全球人工智能與GPU計算領域最具影響力的技術盛會——NVIDIA GTC 2026大會上,阿里云資深技術總監張為受邀發表演講,帶來了《基于全局KV Cache存儲系統的高效LLM推理加速方案》的深度分享。
這不是一次普通的技術發言。NVIDIA GTC大會匯聚了全球頂尖的AI科學家、工程師與產業領袖,每一個受邀Session都經過嚴苛篩選。這次入選,不僅是對阿里云Tair在AI推理基礎設施領域多年積累的高度認可,更標志著中國云計算廠商在全球AI底層技術話語權上邁出了關鍵一步。
在AI從"模型能力競爭"轉向"工程效率競爭"的今天,KV Cache管理正成為大模型推理鏈路中最關鍵的性能瓶頸之一。GPU顯存貴、上下文長、并發高——這三重壓力疊加之下,如何用存儲的智慧釋放算力的潛能,是整個行業都在苦尋的答案。
阿里云數據庫 Tair 給出了自己的回答:從分層調度、全局池化、混合模型適配,到與SGLang社區深度共建、聯合NVIDIA Dynamo AIConfigurator 團隊開發高保真仿真器,再到面向未來硬件的G3.5定制存儲探索——一套覆蓋全鏈路的系統性解法,正在重新定義AI時代的存儲基礎設施。
本文是對張為GTC演講的深度復盤與延伸解讀,帶你從原理到架構、從挑戰到未來,完整理解這場正在發生的存算協同革命。
當前,AI 的應用正經歷從“單一模型交互”向“自主智能體(Agent)集群協作”的關鍵范式轉移。隨著 OpenClaw 等新一代框架的爆發,應用側對長上下文、多輪記憶及復雜任務規劃的需求呈指數級增長,基礎設施面臨前所未有的挑戰。在此背景下,阿里云資深技術總監張為在 GTC 2026 Session 中介紹《基于全局KV Cache 存儲系統的高效 LLM 推理加速方案》,這一分享不僅引發了業界的廣泛討論與共鳴,更標志著存儲層在 AI 推理鏈路中的戰略地位從“輔助支撐”向“核心驅動”轉變,確立了存算協同作為突破算力瓶頸的關鍵路徑。本文將以此次分享為核心線索,從 KVCache 的技術原理、架構演進、工程挑戰到未來硬件趨勢,為大家帶來一次系統性的深度復盤與解析,旨在為構建高效、經濟的 AI 推理基礎設施提供實踐參考。
KVCache 作用和應用發展趨勢
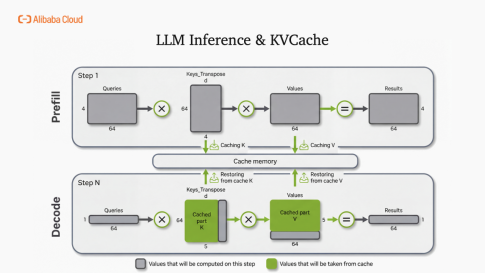
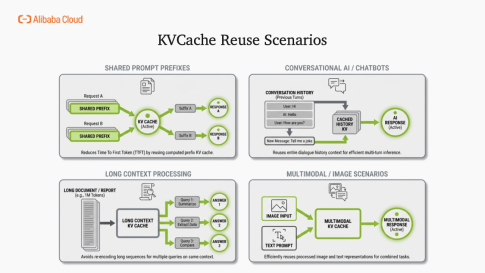
KV Cache 是大語言模型推理的核心優化技術,其本質是"以內存換算力"。在 Prefill 階段緩存 Key/Value 狀態,Decode 階段直接復用歷史緩存,避免重復計算,將冗余的矩陣運算轉化為高效內存讀取,顯著降低延遲與推理成本。
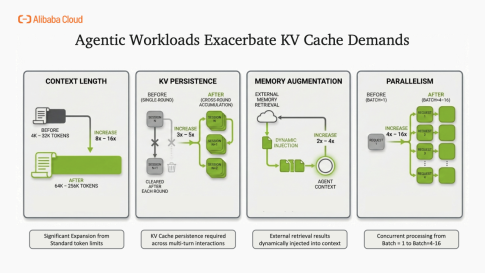
當前,KV Cache 已廣泛應用于系統提示詞復用、多輪對話記憶、長文檔檢索及多模態處理等場景,成為提升生產效能的關鍵。隨著自主智能體時代到來,其需求呈指數級增長:上下文長度從4K擴展至256K tokens、跨輪次緩存持久化、RAG動態注入外部知識、高并發批處理,四大維度疊加使內存壓力激增8-16倍。
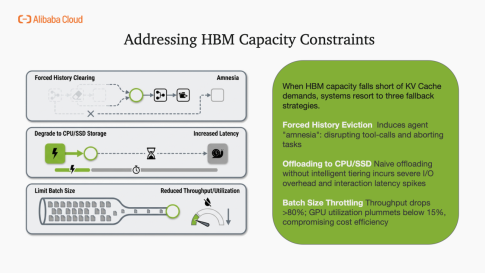
然而,GPU高帶寬內存容量已成為物理瓶頸。傳統方案如強制清除歷史、卸載至CPU或降低批量,均會損害可靠性或實時性。
基于與主流模型廠商的深度研討,針對 OpenClaw 類 Agent 應用及未來多模態 1M 長上下文場景,行業共識已指向構建智能分層、業務感知的 KV Cache 管理體系,這將是突破“內存墻”、釋放智能體潛力的核心方向。具體演進路徑包含三個層面:
1. 存儲智能分層: 建立類似操作系統虛擬內存的多級架構,熱數據駐留 GPU HBM,溫數據卸載至 Host DRAM,冷數據持久化至遠端高性能存儲,實現容量與成本的平衡。
2.業務感知調度: 淘汰策略從簡單的 LRU(最近最少使用)升級為基于任務類別的冷熱數據區分。
3.存算分離與池化: 推動 KV Cache 存儲與計算算力解耦,通過全局資源池化打破單卡顯存限制,為“無限上下文”提供底層支撐。
我們 (阿里云數據庫 Tair KVCache) 在做什么?
我們看到范式轉移:當前正從"移動時代"的孤立應用架構(每應用獨立數據庫),邁向"模型即服務"的超級應用時代。用戶通過統一入口與智能體交互,由底層LLM推理服務并發處理代碼生成、對話、分析等多元任務,實現能力融合與資源集約。
在這一變革中,數據訪問模式發生了根本性變化。傳統的 Transactional Load(交易型負載)正演變為 Inference Load(推理型負載)。阿里云數據庫 Tair KVCache正順勢而為,實現從互聯網時代面向高并發交易,到 AI 時代面向高吞吐推理的戰略延展,成為連接算力與模型的關鍵存儲樞紐。
傳統緩存經驗在 AI 時代的復用
盡管負載類型變了,但存儲系統的核心設計哲學在 AI 推理中依然成立。Tair 將互聯網時代成熟的緩存架構經驗,平滑遷移至 AI 基礎設施中:
傳統互聯網架構 (Mobile Era)AI 推理架構 (MaaS Era)核心價值
統一接口:應用通過 KV 接口 (如 Redis) 訪問緩存統一抽象:推理引擎通過標準 KV 接口訪問 KVCache解耦計算與存儲,屏蔽底層硬件差異
多級存儲:App Local Cache → 遠端分布式緩存 → 持久化 DB顯存層級:GPU HBM → Host DRAM → 遠端高性能存儲 (Tair)冷熱分離,降低高昂的 GPU 顯存成本
預計算加速:緩存復雜查詢或者中間計算結果,避免重復計算,減少DB壓力中間態復用:緩存 Attention 計算中間結果 (Prefix Caching)加速首字延遲 (TTFT),提升推理吞吐量
1. 接口標準化: 正如互聯網應用依賴 Redis 協議,AI 推理引擎同樣需要一個標準的 KV 抽象層。Tair 提供的高兼容 KV 接口,使得推理框架無需關心底層是 DRAM 還是 SSD,實現計算存儲解耦。
2. 存儲層級化: 傳統架構中,本地緩存解決延遲,遠端緩存解決容量。在 AI 中,GPU HBM 極其昂貴且有限,必須將不活躍的 KVCache 快速卸載(Offload)到 Host DRAM 或遠端 Tair 存儲中,實現“無限顯存”。
3. 計算下推與預取: 傳統緩存通過預計算加速查詢;AI 緩存則通過預取(Prefetching)和前綴復用(Prefix Reuse),避免重復計算相同的 Token 序列,直接利用存儲能力加速推理效果。
應對推理上 KVCache 的新挑戰
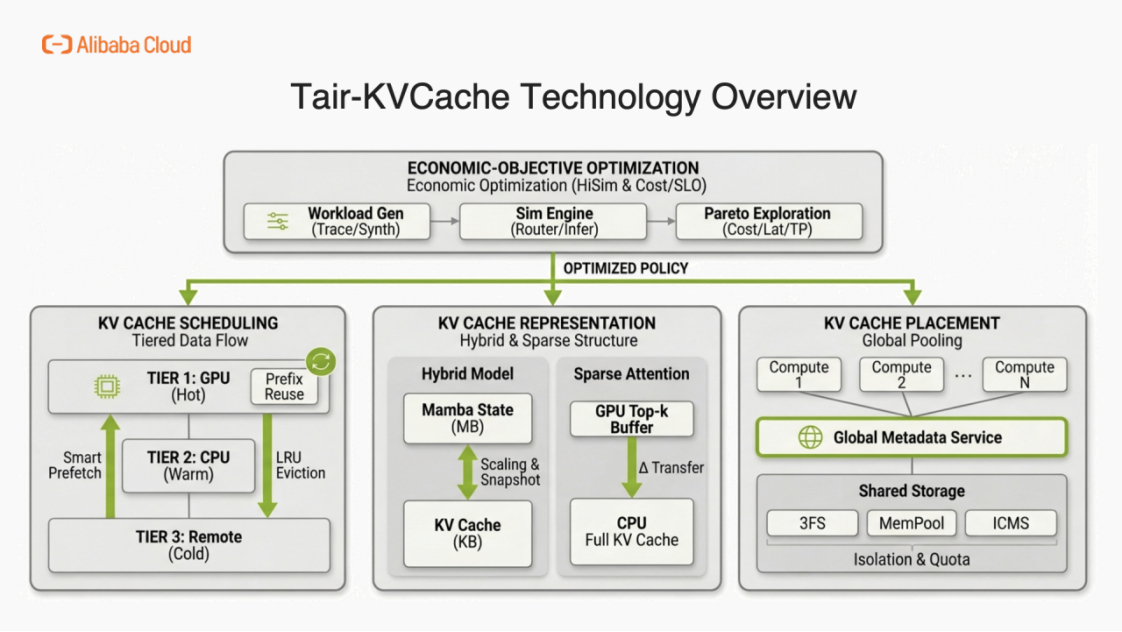
回顧過去一年的技術演進,阿里云數據庫 Tair 深度融入開源生態,與合作伙伴共同補齊了 KVCache 解決方案的關鍵拼圖。針對推理鏈路中的核心痛點,我們從分層調度、模型支持、存儲優化、全局管理,經濟效應及算法創新六個維度進行了系統性優化。
1. 推理引擎調度與分層緩存 (Scheduling & HiCache)針對推理引擎(如 vLLM、SGLang)與存儲間缺乏統一標準的問題,我們與SGLang 社區合作推出了 HiCache 分層緩存體系。該方案通過顯存 - 內存 -3FS 多級卸載與全局共享,解決了存儲綁定嚴重、難以實施多級緩存和智能預取的痛點。緩存命中率提升至 80%,TTFT 降低 56%,推理 QPS 翻倍,支撐智能體時代的大模型高效推理。具體的工作可以參考 阿里云 Tair 聯手 SGLang 共建 HiCache,構建面向“智能體式推理”的緩存新范式
2. 混合模型架構適配 (Hybrid Model Support)隨著模型實現從 Full Attention 快速迭代至 Linear Attention(如 QWen、Kimi)及 Sparse Attention(如 DeepSeek、GLM),我們及時優化了 KVCache 的管理方式。在SGLang 社區中,我們負責實現了對 Mamba-Transformer 等混合架構模型的遠端KVCache 支持及表示層兼容。確保新一代高效模型也能享受存算分離帶來的容量紅利,無需因架構差異而犧牲緩存性能。具體的工作可以參考 Hybrid Model Support:阿里云 Tair 聯合 SGLang對 Mamba-Transformer 等混合架構模型的支持方案 、SGLang Hierarchical Sparse Attention 技術深度解析
3. 元數據管理與全局池化 (KVCache Manager)
針對 Agent 長會話、高并發導致的調度與命中率沖突,我們建設 Tair KVCache Manager。基于高性能網絡實現 KVCache 全局池化,引入 LLM 語義層 抽象管理元數據,向上暴露原生接口,向下高效調度存儲,兼顧落地速度與長期演進。實現存算徹底解耦,支持推理容器彈性伸縮而不影響緩存命中率;提供 ROI 評估、可觀測性及高可用等企業級能力,顯著降低 GPU 消耗并提升服務質量。具體的工作可以參考我們和集團RTP-LLM開源共建的 阿里云 Tair KVCache Manager:企業級全局 KVCache 管理服務的架構設計與實現
4. 高性能遠端存儲落地
針對 KVCache 對帶寬與容量的雙重需求,我們和服務器團隊以3FS為基座,通過 RDMA 全鏈路加速、GDR 零拷貝、小 I/O 調優及云原生 Operator 等系統性升級,打造專為 LLM 推理優化的 L3 存儲層,并與 SGLang/vLLM 深度集成。實現 20GB/s+ 單節點帶寬與 PB 級彈性容量,長上下文場景 TTFT 下降 78%、推理吞吐提升 520%,在保障低延遲的同時顯著降低單位存儲成本。具體的工作參考:阿里云 Tair 基于 3FS 工程化落地 KVCache:企業級部署、高可用運維與性能調優實踐
5. 經濟效應模擬與 ROI 評估 (Simulation & ROI)
面對 MaaS 時代負載波動大、配置空間爆炸的"黑盒"挑戰,我們和NVIDIA Dynamo團隊聯合推出 Tair-KVCache-HiSim 高保真仿真器。采用分層解耦 + 事件驅動架構,支持端到端推理流程建模與細粒度時延預測,實現配置空間的帕累托最優搜索。仿真成本降低 39 萬倍、端到端誤差<5%,幫助客戶從"經驗規劃"轉向"數據驅動",在滿足 SLO 約束下快速定位成本 - 延遲 - 吞吐的最優平衡點。具體的工作參考: 阿里云Tair KVCache仿真分析:高精度的計算和緩存模擬設計與實現
6. 算法優化與多模態支持 (Algorithm)
針對多模態輸入重復場景,我們與通義實驗室聯合推出 VLCache 緩存復用框架。首次形式化識別"累積復用誤差效應",提出層感知動態重計算策略,協同復用 KV Cache 與 Encoder Cache,僅需計算 2–5% tokens 即可實現準確率持平。TTFT 加速 1.2–16 倍,顯著降低多模態場景顯存占用與計算成本;基于 SGLang 的工程實現,支持實際部署中的高效推理。同時KVCache量化,壓縮,稀疏化的工作正在積極和各大高校和實驗室合作,相關的學術研究工作正在投遞中。 具體的工作參考:VLCACHE: Computing 2% Vision Tokens and Reusing 98% for Vision–Language Inference
此前,業界 KVCache 方案往往局限于單一環節(如僅優化引擎或僅做存儲),缺乏統一標準、全局管理及效果評估手段,導致落地困難、成本不可控。Tair KVCache 通過上述六大模塊,首次實現了從引擎調度、存儲底座、元數據管理、仿真評估到算法優化的全鏈路覆蓋。這不僅補齊了行業在標準化、可觀測性及經濟性評估上的缺失環節,我們還聯合清華、火山 、騰訊、華為等業內伙伴,共同推動 KVCache 服務化標準的制定,為 Agent 時代的大模型推理提供了堅實、完整的基礎設施底座。
AI Memory對于未來存儲的演進需求

理想KV Cache存儲的5大支柱
●帶寬-容量解耦。核心訴求是TB級存儲容量與IOPS性能能夠獨立擴展,解決的問題是不再為了達到帶寬目標而"被迫購買額外容量",降低資源浪費。
●彈性容量。核心訴求是支持平滑擴容、按需付費,解決的問題是避免資源閑置帶來的成本浪費,提升資源利用效率。
●可預測低延遲。核心訴求是嚴格滿足TTFT(首token時間)的SLA要求,解決的問題是保障每個請求的用戶體驗一致性,避免長尾延遲影響服務質量。
●負載-存儲匹配。核心訴求是根據不同工作負載的訪問模式,匹配最適合的存儲介質類型,解決的問題是延長SSD使用壽命,同時優化整體成本結構。
●最優總擁有成本(TCO)。核心訴是在綜合考慮硬件采購、運維管理、能源消耗等所有成本因素后,實現整體成本最優,這是技術方案商業可持續的關鍵。
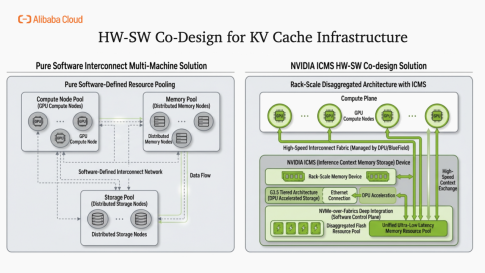
軟硬結合KV Cache定制的G3.5存儲
與傳統通用存儲方案相比,G3.5方案有四個核心差異:第一定位上專為KV Cache優化,而非通用數據存儲;第二接入方式采用網絡附加+智能預取,而非簡單的本地或網絡掛載;成本效率上實現容量與帶寬獨立擴展,按需付費,避免資源浪費。
ICMS 核心能力包括三點:上下文智能放置(決定哪個KV數據塊存放在哪個位置)、硬件級加密(保障數據安全的同時不拖累性能)、塊級追蹤(精準預取數據,減少冗余傳輸)。性能指標達到800Gbps線速處理。關鍵價值在于繞過CPU,實現GPU與Flash存儲之間的直連,大幅降低延遲。
Tair-KVCache負責全局調度決策。NVMe-over-Fabrics深度集成兩者協同的效果是讓遠程閃存在應用層面"看起來像本地內存",對上層透明。此時我們在積極和NVIDIA以及云存儲團隊探索定制 KVCache存儲的后續發展。
硬件突破展望
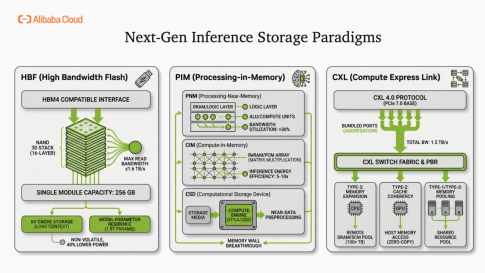
我們和服務器團隊在積極探索下一代 KVCache 存儲介質的選型和發展。
●HBF(High Bandwidth Flash)高帶寬閃存 將HBM(高帶寬內存)采用的3D堆疊技術直接應用于標準NAND閃存芯片。性能飛躍:單棧可實現1.6TB/s的讀取帶寬,相當于當前頂級SSD性能的50倍。應用想象:百萬token級別的KV Cache可以直接"貼近"GPU部署,獲得接近HBM的訪問速度、閃存的大容量優勢,同時不產生額外功耗負擔。
●PIM(Processing-in-Memory)存內計算。 在存儲芯片內部嵌入輕量級計算單元,實現"計算向數據移動"。范式轉變:傳統模式是把原始tensor數據從存儲搬到GPU進行計算,容易遇到網絡帶寬瓶頸;新模式是在存儲端直接完成attention分數等關鍵計算,只將最終的小結果通過網絡傳輸。核心價值:大幅減少數據搬運量,從根源上突破"內存墻"限制。
●CXL 4.0 + PCIe 7.0:互聯協議革命 帶寬相比CXL 3.0翻倍;新增"Bundled Ports"技術,支持多鏈路聚合;跨機架內存池帶寬可達1.5TB/s。架構意義:讓"內存"真正成為可池化、可共享的資源,打破單機內存容量限制,為大規模模型推理提供彈性內存支持。