當業界目光聚焦于DeepSeek新一代旗艦模型V4的潛在發布時,該團隊卻以另一種形式引發關注——聯合北京大學、清華大學發表的學術論文,將大模型優化方向轉向了長期被忽視的推理效率領域。這項研究針對智能體系統運行中普遍存在的性能瓶頸,提出了一套突破性的底層架構解決方案。
研究背景揭示了大模型演進帶來的新挑戰:隨著AI從單輪對話向自主智能體轉型,交互輪次呈現指數級增長。在需要處理數十甚至上百輪對話的場景中,模型推理的主要耗時不再來自計算過程,而是源于從硬盤反復讀取長上下文緩存。傳統架構中,預處理引擎獨占網卡帶寬導致解碼引擎閑置的現象,成為制約系統整體效能的關鍵因素。
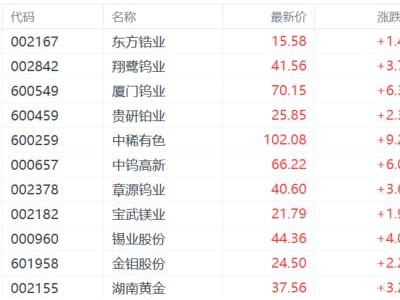
行業對此呈現兩極評價。部分技術從業者認為,這種工程優化是顯卡資源不足背景下的權宜之計,相較于模型架構創新屬于"苦力活"。但另一些觀點指出,即便在算力充足的情況下,此類優化仍具有戰略價值——推理成本每降低一個數量級,都可能催生新的應用場景和市場空間。當前主流模型的token價格仍維持在較高水平,成為阻礙大規模商用的重要因素。
相較于學術成果,市場更關注DeepSeek的模型發布動態。近期關于V4的傳聞呈現多元化特征:有消息稱團隊正在測試代號為"Sealion-lite"的輕量化版本,該模型支持100萬token上下文窗口并具備原生多模態能力;另有爆料指出,華為等國內硬件廠商已獲得V4的提前訪問權限,用于優化處理器與模型的協同效率,而國際芯片巨頭尚未進入合作名單。
面對持續發酵的猜測,DeepSeek保持其一貫的沉默策略。這種態度反而加劇了市場的緊張情緒,部分金融機構開始模擬新一代模型發布可能引發的行業震蕩。去年某頭部企業模型更新曾導致相關概念股單日波動超過15%,此次V4若如期發布,其技術突破與商業策略的組合拳或將重塑競爭格局。當前,整個AI領域都在等待這個可能改變游戲規則的時刻到來。