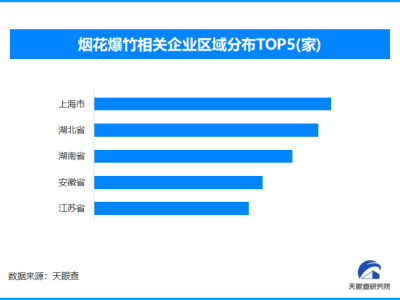
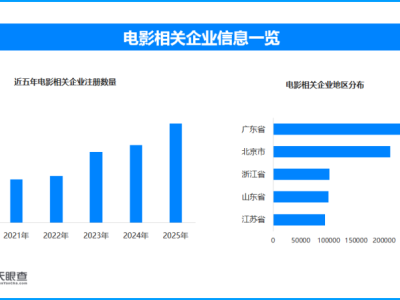
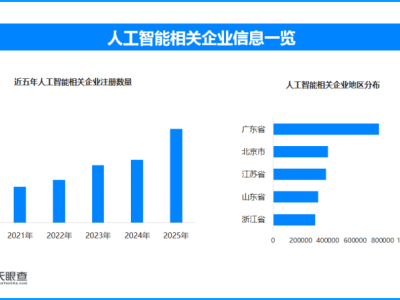
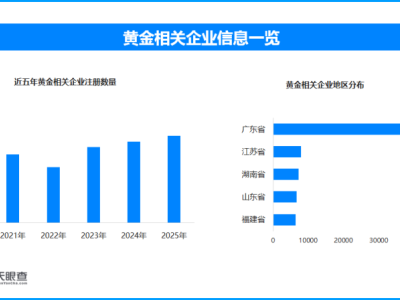
近日,一場關(guān)于 AI 架構(gòu)起源的爭論在社交媒體上鬧得沸沸揚(yáng)揚(yáng)。被譽(yù)為“歐洲版 OpenAI”的MistralCEO Arthur Mensch 在接受訪談時表示,中國強(qiáng)勁的開源模型DeepSeek-V3實(shí)際上是基于 Mistral 提出的架構(gòu)構(gòu)建的。此番言論一出,立即引來了全球開發(fā)者和網(wǎng)友的圍觀與質(zhì)疑。
核心爭議:是“致敬”還是“自主創(chuàng)新”?
Arthur Mensch 在訪談中提到,Mistral 在2024年初發(fā)布了首個稀疏混合專家模型(MoE),而他認(rèn)為 DeepSeek 隨后的版本都是在此基礎(chǔ)上構(gòu)建的,稱其“采用了相同的架構(gòu)”。
然而,嚴(yán)謹(jǐn)?shù)木W(wǎng)友通過查閱 arXiv 上的原始論文發(fā)現(xiàn)了疑點(diǎn):
發(fā)布時間膠著:Mixtral的論文與DeepSeek MoE論文的發(fā)表時間僅相差3天,很難界定誰真正影響了誰。
架構(gòu)思路迥異:雖然兩者都屬于稀疏混合專家系統(tǒng)(SMoE),但 Mixtral 更偏向工程優(yōu)化,而 DeepSeek 在算法上進(jìn)行了深度重構(gòu)。
專家設(shè)計不同:DeepSeek 引入了“細(xì)粒度專家分割”和“共享專家”機(jī)制,將通用知識與特定知識解耦,這與 Mixtral 的扁平化專家設(shè)計有本質(zhì)區(qū)別。
技術(shù)反轉(zhuǎn):誰在“歲月史書”?
令人玩味的是,這場爭論很快出現(xiàn)了反轉(zhuǎn)。有技術(shù)專家指出,與其說 DeepSeek 借鑒了 Mistral,倒不如說情況可能相反。
架構(gòu)回流:2025年底發(fā)布的Mistral3Large被網(wǎng)友扒出,其底層架構(gòu)反而與 DeepSeek-V3采用的 MLA 等創(chuàng)新技術(shù)高度相似。
影響力變遷:網(wǎng)友調(diào)侃稱,Mistral 似乎在試圖通過“改寫歷史”來挽回技術(shù)領(lǐng)先地位的流失,因為 DeepSeek 在 MoE 架構(gòu)的創(chuàng)新上顯然獲得了更大的行業(yè)影響力。
AI 界的“共同進(jìn)步”還是“嘴炮大戰(zhàn)”?
盡管存在爭論,但正如 Mensch 在訪談前半部分所說,開源精神的核心在于“大家在彼此的基礎(chǔ)上不斷進(jìn)步”。
競爭白熱化:DeepSeek已被曝瞄準(zhǔn)2026年春節(jié)檔,準(zhǔn)備發(fā)布更強(qiáng)的新模型。
開源之爭:Mistral 也在持續(xù)更新其Devstral家族,試圖奪回開源編程智能體的高地。
這場“口水仗”背后,反映出全球頂尖 AI 實(shí)驗室在技術(shù)迭代速度上的極度焦慮。在代碼與公式面前,單純的口頭宣誓往往無力,真正的勝負(fù)終將在模型性能的實(shí)測中揭曉。