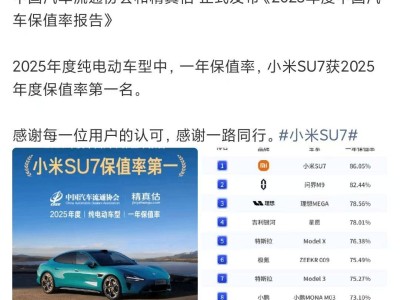
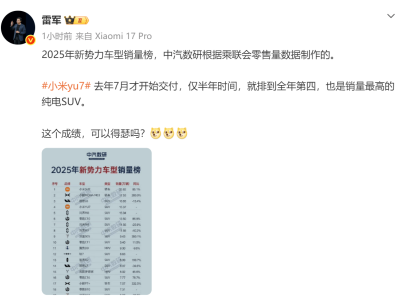
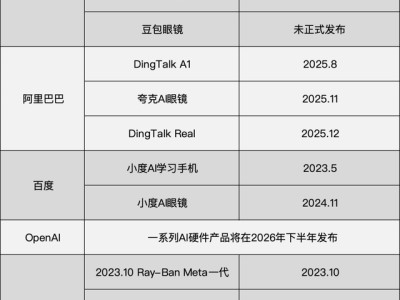
谷歌DeepMind團隊近日宣布,在Gemini 3 Flash模型中引入了一項突破性的“智能體視覺”功能。這一創新旨在解決傳統AI模型在圖像處理中的固有局限,通過主動調查的方式提升視覺理解的準確性。
傳統AI模型在處理圖像時,往往僅進行一次靜態掃描。這種方式容易遺漏關鍵細節,例如芯片序列號或遠處路牌上的信息,導致模型只能依賴猜測生成答案。Gemini 3 Flash的新功能則通過模擬人類的“思考、行動、觀察”循環,將視覺理解轉化為一個動態過程。模型不再被動接收信息,而是主動制定計劃、操作圖像并驗證結果,從而確立答案的視覺證據。
“智能體視覺”的核心機制是一個閉環系統。在“思考”階段,模型分析用戶查詢和初始圖像,制定多步操作計劃;隨后進入“行動”階段,模型生成并執行Python代碼,對圖像進行裁剪、旋轉或標注等操作,或進行邊界框計算等分析;最后在“觀察”階段,變換后的圖像被追加到模型的上下文窗口中,供進一步驗證。這一過程使模型能夠利用更新后的數據和更佳的語境進行二次檢查,最終生成基于事實的回復。
引入代碼執行能力后,Gemini 3 Flash在多項視覺基準測試中的表現顯著提升,質量提高了5%至10%。例如,在建筑圖紙驗證平臺PlanCheckSolver.com上,該功能通過代碼裁剪并分析屋頂邊緣等高分辨率細節,使準確率提升了5%。在處理視覺數學問題時,模型不再依賴概率猜測,而是通過編寫代碼識別原始數據并調用Matplotlib庫繪制精確圖表,有效解決了多步視覺算術中常見的“幻覺”問題。
目前,Gemini 3 Flash已能夠隱式決定何時放大細節以獲取更準確的信息。谷歌DeepMind團隊表示,未來版本將進一步優化,無需用戶顯式提示即可自動執行旋轉圖像或視覺運算等操作,從而提供更智能、更高效的視覺理解服務。