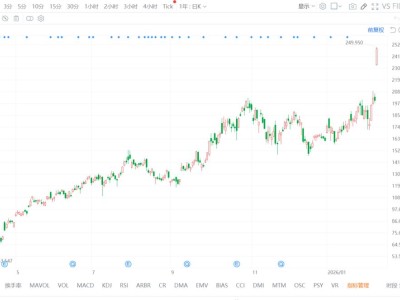
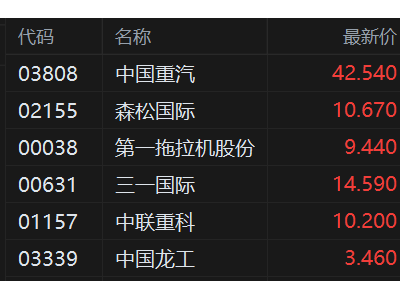
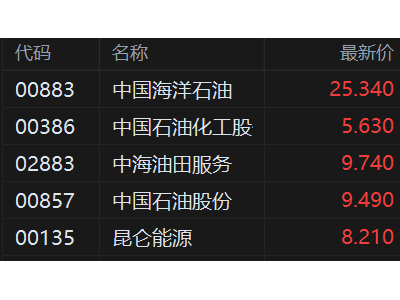
格隆匯2月12日|字節跳動宣布正式發布新一代視頻創作模型Seedance 2.0。Seedance 2.0采用統一的多模態音視頻聯合生成架構,支持文字、圖片、音頻、視頻四種模態輸入,集成了目前業界最全面的多模態內容參考和編輯能力。相比1.5版本,Seedance 2.0的生成質量大幅提升,其在復雜交互和運動場景下的可用率更高,物理準確度、逼真度、可控性顯著增強,更加貼合工業級創作場景的需求。其核心亮點如下:
復雜場景下更高可用率:憑借出色的運動穩定性和物理還原能力,模型在多主體交互和復雜運動場景中表現出色,生成可用率達到業界SOTA水平。
多模態能力顯著強化:基于統一的多模態音視頻聯合架構訓練,支持混合模態輸入,允許用戶同時輸入多達9張圖片、3段視頻、3段音頻以及自然語言指令,模型可參考輸入素材中的構圖、動作、運鏡、特效、聲音等元素,打破傳統視頻生成的素材邊界。
視頻生成可控性大幅提升:模型的指令遵循與一致性表現全面提升,并支持穩定可控的視頻延長、視頻編輯,讓普通用戶也能像導演一樣,輕松掌控視頻創作全流程。
深度支持工業級內容創作:模型支持15秒高質量多鏡頭音視頻輸出,具備雙聲道音頻能力,可實現極致擬真的視聽效果,配合參考和編輯能力,能大幅降低影視、廣告、電商、游戲等場景的內容制作成本。
復雜場景下更高可用率:憑借出色的運動穩定性和物理還原能力,模型在多主體交互和復雜運動場景中表現出色,生成可用率達到業界SOTA水平。
多模態能力顯著強化:基于統一的多模態音視頻聯合架構訓練,支持混合模態輸入,允許用戶同時輸入多達9張圖片、3段視頻、3段音頻以及自然語言指令,模型可參考輸入素材中的構圖、動作、運鏡、特效、聲音等元素,打破傳統視頻生成的素材邊界。
視頻生成可控性大幅提升:模型的指令遵循與一致性表現全面提升,并支持穩定可控的視頻延長、視頻編輯,讓普通用戶也能像導演一樣,輕松掌控視頻創作全流程。
深度支持工業級內容創作:模型支持15秒高質量多鏡頭音視頻輸出,具備雙聲道音頻能力,可實現極致擬真的視聽效果,配合參考和編輯能力,能大幅降低影視、廣告、電商、游戲等場景的內容制作成本。