
整個具身智能領域都在探索世界模型的實用化路徑。這個被寄予厚望的「數字模擬器」,本應成為機器人訓練的核心工具,卻因物理保真度低等問題成為「空中樓閣」。
去年年中,谷歌發布了 Genie-3 世界模型,讓「可交互的世界模型」第一次以極具沖擊力的方式走進大眾視野。這是一個可以實時生成、實時交互的「無限世界」:通過控制動作,用戶可以展開幾乎無限的場景演化路徑。
這一能力也迅速被投射到具身智能領域 —— 如果機器人也能在這樣的世界模型中進行億萬次的訓練,是否意味著通用機器人真的觸手可及?
但當研究者真正嘗試將「可交互世界模型」用于機器人學習時,很快發現了一些繞不開的本質問題:
1)世界模型擅長「看起來對」,卻難以做到「物理上對」;
2)由于機器人數據大部分都是成功的 demo,世界模型總是過于樂觀;
結果是:世界模型的不準確性 + 過度樂觀的動力學假設,使得 VLA 策略幾乎無法在其中穩定學習。

世界模型「盲目樂觀地」自動補全了殘缺的形狀;世界模型「錯誤地」將真實世界里倒塌的方塊誤認為堆疊狀態。
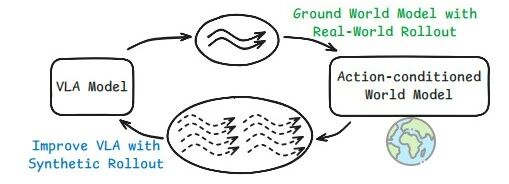
清華陳建宇(星動紀元創始人)團隊和斯坦福 Chelsea Finn(PI 創始人) 團隊基于 Ctrl-World (兩個團隊的首個合作成果),再度攜手,聯合提出了 VLAW 框架,首次實現了 VLA 策略與動作條件世界模型的協同迭代優化,讓兩者形成一個「互相促進的閉環」:
VLA 策略采集的真實交互數據,反過來用于提升世界模型的物理保真度;
世界模型生成的高質量虛擬數據,再用于持續強化 VLA 策略本身。

論文鏈接:https://arxiv.org/pdf/2602.12063
GitHub 地址:https://github.com/Robert-gyj/Ctrl-World
機器人學技能
試錯的「學費」貴到離譜
世界模型成關鍵期待
每次在真實機器人上的試錯(真機 rollout),都需要人工重置環境;一旦模型策略出錯,機械臂還可能做出危險操作,必須有人全程盯著。真實世界的后訓練數據規模,就這樣被死死卡住了脖子,成了具身智能發展的核心瓶頸。
能讓機器人在「想象空間」無限試錯的世界模型,成為解決這一問題的關鍵期待 —— 在完美的世界模型里,機器人能在這個「想象空間」里無限試錯,生成海量合成數據練手,完全不用碰真實世界里昂貴的硬件設備,試錯成本能降到幾乎為零。
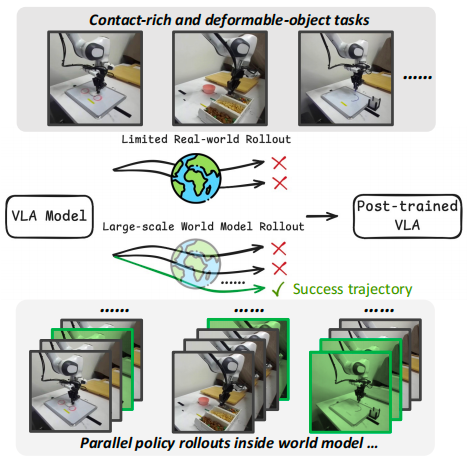
VLA 模型在真實世界的 rollout 耗時且難以擴展。在 VLAW 中,首先利用有限的真實世界在線 rollout 學習一個動作條件的世界模型,進而在想象中生成大規模的合成數據
世界模型:
一座美輪美奐的「空中樓閣」
理想很豐滿,現實很骨感。現有世界模型存在二個致命缺陷,讓它成了一座「空中樓閣」,最終只會落得「垃圾進,垃圾出」的下場,讓世界模型的實用化成為空談。
盲目樂觀:訓練數據大多是成功的動作軌跡,沒見過失敗案例,導致模型預測的結果全是「理想情況」,根本還原不了真實操作中的失誤和意外,無法貼合真實的操作場景;
交互、碰撞模擬困難:對于物體碰撞、摩擦這類接觸密集型操作,或是紙巾、書本這類可變形物體的交互,模型根本捕捉不到那些微小但關鍵的物理細節,甚至會生成模糊的畫面,喪失了物理建模的核心價值;
VLAW 破局:
讓 VLA 和世界模型雙向奔赴
打磨出實用的世界模型
VLA 策略在線 rollout 數據有助于將預訓練的世界模型適配到下游任務中。一旦世界模型完成適配,就能為 VLA 策略學習生成海量數據
VLAW 的核心解法,讓 VLA 策略的真實數據校準世界模型,以校準后的世界模型反哺 VLA 策略,在這個雙向奔赴的過程中,世界模型的缺陷被逐一解決,物理保真度和數據生成能力持續提升。
四步走:
把「讓世界模型有用」的想法落地成工程
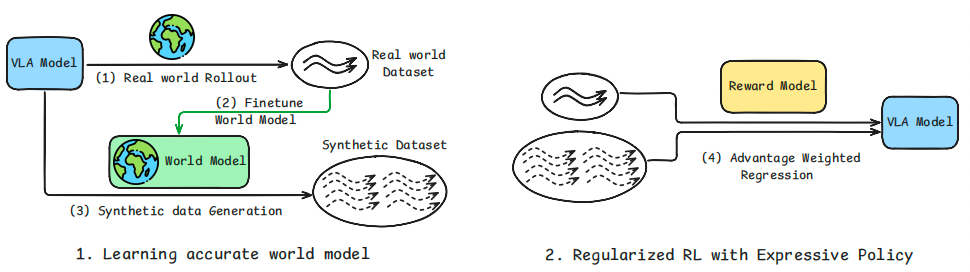
VLAW 的工作流程:(1) 首先在真實世界中執行策略以收集少量在線軌跡;(2) 利用這些策略 rollout 數據微調預訓練的動作條件世界模型,使世界模型適配目標任務并提升其預測保真度;(3) 利用優化后的世界模型,通過策略與世界模型的閉環交互生成大規模合成軌跡;(4) 最終,利用視覺 - 語言獎勵模型自動評估獎勵,結合真實世界和合成數據優化 VLA 策略
從理論思路到實際落地,VLAW 設計了四個精密咬合的步驟,通過迭代優化實現「讓世界模型有用」的核心目標,同時讓機器人借助校準后的世界模型完成「在想象中變強」的訓練。
第一步:使用真實 rollout 數據微調世界模型,戒掉盲目樂觀
研究團隊用包含成功與失敗的真實機器人在線軌跡數據微調預訓練世界模型;同時為了防止模型過擬合,還加入了原始的 DROID 數據集一起訓練,讓它既能看懂失敗,又不會過擬合,確保對真實場景的還原度。
第二步:使用 Qwen-VL 評判軌跡
團隊基于 Qwen3-VL-4B-Instruct 微調了一個視覺 - 語言獎勵模型,用真實數據里的成功 / 失敗標簽校準它的判斷能力,能自動判別世界模型生成數據的好壞。
第三步:在世界模型中生成大量數據
在校準后的世界模型里,讓機器人策略進行大規模的 rollout,每個任務都生成 500 條合成軌跡。這一步就是機器人在「想象中」練手,但因為世界模型已經被真實數據校準,這些「想象中的數據」的質量大大提升。
第四步:學成功樣本優化策略,反向為世界模型校準提供更優質數據
把真實世界里的成功軌跡,和世界模型生成的優質合成成功軌跡混在一起,用簡單的監督學習目標來更新機器人的 VLA 策略。原因很實際:對于流匹配、擴散這類生成式策略,強化學習需要計算特定狀態下的動作概率密度,但這類策略的動作是從噪聲一步步推導出來的,概率計算難度極高。團隊還從理論上證明,這種加權回歸目標,其實是正則化強化學習的一種近似形式,兼顧了簡單性和有效性。
而 VLA 策略的優化與性能提升,又能在真實世界中產生更優質的試錯數據,為世界模型的下一輪校準與優化提供更好的基礎,形成世界模型與 VLA 策略互相成就的閉環。
實測見真章:
模擬器從「空想家」變「務實者」
研究團隊設計了一個動作重放的評估方法:把真實機器人的動作序列輸入世界模型,讓它生成對應的視頻,再和真實世界的視頻對比,從視頻質量和物理交互結果兩個維度做定量評估:
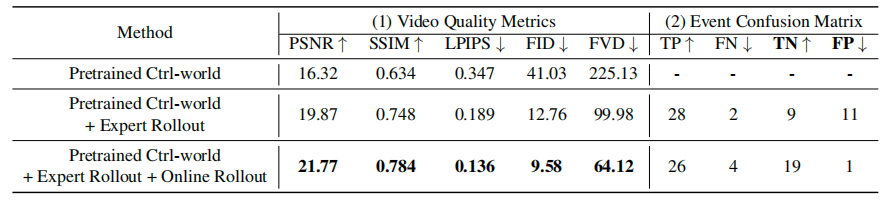
在世界模型中重放記錄的動作序列。(1) 在 256 個重放片段(每個 5 秒)上評估視頻質量指標,所有指標均通過腕部視角相機計算,該視角最能捕捉操作過程中的物體交互;(2) 交互階段是誤差的主要來源,因此在 50 個涉及物理交互的片段上報告事件級混淆矩陣,為每個片段標注交互結果(成功 / 失敗),并將模型預測與真實世界結果對比
結果一目了然:
1. 經過真實試錯數據微調后的世界模型,在 PSNR、SSIM 等視頻質量指標上,全面超過了原始預訓練模型,以及僅用專家成功數據微調的模型,生成的視頻畫面更貼合真實;
2. 更重要的是,它的假陽性率大幅降低,再也不會把失敗的操作「腦補」成成功,精準解決了「樂觀病」,能真實還原操作中的成敗結果。

在相同的初始幀和完全相同的動作序列條件下,在不同世界模型中執行軌跡推演。預訓練的 Ctrl-World 模型對于這些接觸密集型任務的精度不足;僅用專家軌跡微調的世界模型往往過于樂觀;相反,用策略在線 rollout 數據微調的世界模型能準確捕捉底層的物理動力學,與真實世界的結果高度吻合。
3. 哪怕是 20 秒的長時程虛擬試錯,生成的視頻也能保持較高的物理合理性。


從初始觀測開始,在世界模型中進行長時程策略閉環 rollout 的示例。π0.5 策略執行 20 次迭代(20 秒),微調后的世界模型與真實世界高度一致。上:真實世界 下:世界模型
比如舀花生入碗、用紙巾擦白板標記這類需要精準物理交互的任務,預訓練的世界模型完全抓不住細節,僅用專家數據微調的模型則過于樂觀,而經 VLAW 校準的世界模型,能精準捕捉底層的物理動力學,生成的結果和真實世界高度吻合。
關鍵數字:
校準后的世界模型
支撐機器人復雜任務性能大幅躍升

實驗在 DROID 平臺上開展,涵蓋五類任務,如圖所示。這些任務涉及復雜的物理交互,包括頻繁的接觸和可變形物體,難以在傳統仿真中建模。
研究團隊在 DROID 機器人平臺上,針對堆疊積木、打開書本、擦除白板標記、舀取顆粒、畫圓五類復雜任務做了實測 —— 這些任務都涉及頻繁的物理接觸或可變形物體操作,是傳統仿真模型很難建模的場景,也正是檢驗世界模型實用價值的關鍵場景。實驗用當前 SOTA 的 π0.5 作為基礎策略,Ctrl-World 作為基礎世界模型,每輪迭代在 5 類任務上共收集 250 條真實軌跡(每類任務 50 條)用于世界模型的校準,而經校準后的世界模型,最終交出了一份亮眼的成績單,支撐機器人策略在五類任務中實現成功率的大幅提升。從整體表現來看,各方法的成功率提升對比結果清晰顯示 VLAW 的優勢。
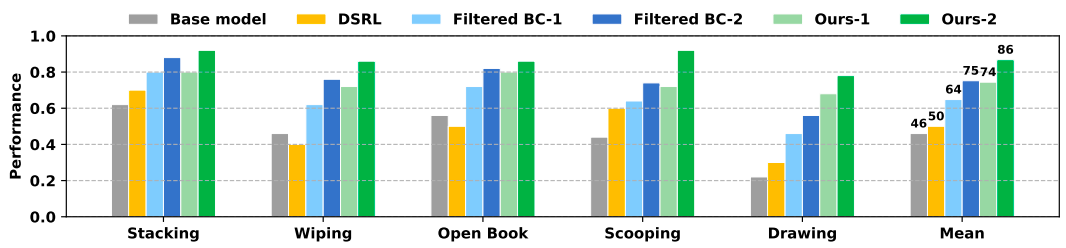
與基線方法的成功率提升對比。進行了兩輪迭代訓練,「Ours-1」表示 VLAW 方法經過第一輪在線 rollout 后的結果。總體而言,在多任務設置下 VLAW 持續優于 Filtered BC 和 DSRL 基線
團隊還可視化了真實 rollout 與世界模型生成的合成 rollout 對比,清晰展現了經校準后的世界模型,能為真實世界的失敗案例找到成功的解決路徑,其生成的合成數據具備極高的訓練價值。在真實世界 rollout 中,機器人未能抓住勺子、未能畫出完整的圓,而借助 VLAW 打磨后的世界模型,能從相同初始幀出發,為這些失敗案例生成成功的軌跡,讓機器人能從「失敗經驗」里學會正確的做法,這正是世界模型實用化的核心體現。

GT 代表真實世界的 rollout,0~14 代表世界模型生成的多種想象軌跡,所有軌跡均從相同的 GT 初始幀出發并使用 π0.5 策略。在真實世界 rollout 中,機器人未能抓住勺子(左,GT)且未能畫出完整的圓(右,GT)。借助世界模型,我們能為這些失敗案例找到成功的軌跡,這對策略學習具有重要意義
不僅如此,消融實驗還進一步證明了 VLAW 打磨世界模型的核心邏輯:如果減少世界模型生成的合成數據的數量,或是直接移除校準世界模型的真實數據,機器人策略的性能都會明顯下降。這意味著,世界模型的校準質量和合成數據產出量,直接決定了機器人策略的提升效果,也再次印證了「讓世界模型變得有用」是 VLAW 框架的核心關鍵。
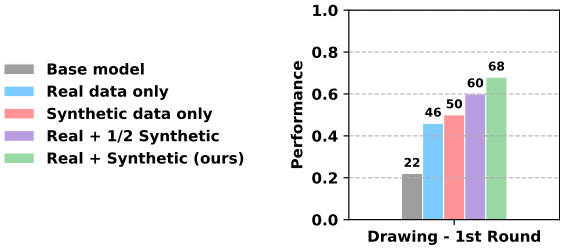
消融實驗研究了 (1) 用于策略微調的合成數據量(從 500 條減少到 250 條)和 (2) 微調時是否包含真實世界 rollout 數據(50 條)。實驗發現,減少合成軌跡數量或移除真實世界數據集都會導致性能下降
未來:
機器人先在想象里「滿級」
再落地真實生活
目前 VLAW 的實驗驗證集中在五類任務上,研究團隊表示,未來的研究將圍繞世界模型的規模化和泛化性展開,持續提升世界模型的能力,讓其能適配更多場景、更強的模型,真正成為通用機器人策略學習的核心工具:
一是把真實試錯數據擴展到更多樣的機器人操控任務中,提升世界模型的通用泛化能力;
二是結合更先進的視頻生成模型,讓世界模型的視覺預測和物理建模能力更上一層樓。
在研究團隊看來,隨著視頻生成模型的持續發展,以及大規模機器人交互數據的不斷積累,讓世界模型變得更通用、更精準、更實用,并基于打磨后的世界模型構建訓練范式,將成為通用機器人策略學習的核心方向。
未來的機器人,或許會先在由優質世界模型打造的虛擬世界里完成「滿級訓練」,把各種技能練到爐火純青,再無縫落地到真實世界,從容完成各類復雜的操控任務。而 VLAW,正是世界模型實用化的重要探索,為這一未來方向奠定了堅實的基礎。











