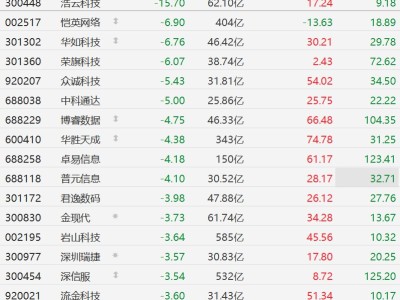
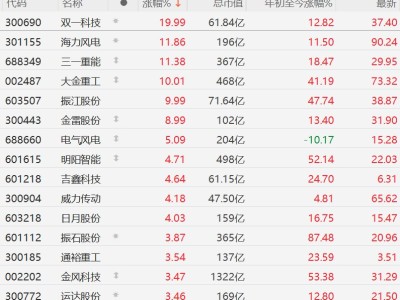
谷歌近日推出全球首個原生多模態嵌入模型Gemini Embedding 2,標志著人工智能技術向跨模態理解邁出關鍵一步。該模型突破傳統單一模態處理框架,首次實現文本、圖像、視頻、音頻及PDF文檔五種數據類型的統一向量空間映射,為機器構建起跨媒體語義理解的基礎設施。
傳統人工智能系統在處理多模態數據時面臨顯著挑戰:文本、圖像、音頻等不同類型數據需通過獨立模型轉換為向量表示,導致語義關聯分析需依賴復雜的數據對齊算法。Gemini Embedding 2通過創新架構設計,使不同模態數據在向量空間中自然關聯,支持"文字+圖片""視頻+音頻"等混合輸入模式。這種技術突破使得用戶可用文字檢索圖像,或通過圖像定位相似音頻片段成為現實。
該模型的核心價值在于重構多模態數據處理流程。對于AI開發者而言,過去需要維護多套嵌入系統并編寫結果對齊代碼的復雜工作,現在可通過單一模型完成。以音視頻處理場景為例,開發者可直接輸入原始數據,無需進行語音轉文字或視頻抽幀等預處理步驟,既減少信息損耗又降低開發成本。媒體行業可借此建立跨格式素材庫,編輯通過自然語言描述即可精準檢索視頻片段,擺脫人工標注的效率瓶頸。
在檢索增強生成(RAG)領域,Gemini Embedding 2推動技術范式升級。傳統RAG系統僅支持文本檢索,新模型可同步檢索圖表、視頻等多媒體內容作為上下文。當用戶提出復雜問題時,系統能提供圖文并茂的回答,顯著提升信息密度與交互體驗。醫療、金融等擁有海量非結構化數據的企業,可通過該模型激活沉睡的數據資產,實現智能化的跨模態知識檢索。
技術基準測試顯示,Gemini Embedding 2在文本、圖像、視頻任務中均超越主流競品,重新定義多模態嵌入性能標準。其應用場景覆蓋法律證據檢索、個性化推薦系統等多個領域。法律從業者可從海量記錄中快速定位包含特定圖像或音頻的證據文件;推薦系統能基于用戶行為混合推薦文章、視頻與播客內容,實現更自然的交互體驗。
這款模型的發布恰逢全球多模態技術發展關鍵期。2026年以來,國內科技企業密集推出新一代多模態模型,推動AI視頻生成從娛樂應用向工業級生產轉型。某企業發布的模型通過創新交互范式,允許用戶指定素材用途并生成物理規律更合理的畫面。當前行業趨勢顯示,多模態大模型正從簡單拼接轉向原生融合,統一表示空間架構成為技術演進的主流方向。
Gemini Embedding 2的突破性在于重構機器理解世界的底層邏輯。通過建立統一的向量表示體系,不同模態數據得以在語義層面深度關聯,為構建真正"全感知"的人工智能系統奠定基礎。這項技術革新不僅簡化現有應用開發流程,更將催生大量此前難以實現的創新應用場景。