理想汽車創始人李想近日在社交平臺發布長文,深入剖析了自動駕駛領域長期面臨的技術瓶頸,并首次公開了理想汽車突破行業困境的創新方案。他指出,人類駕駛員在幼年時期便通過日常活動構建了對三維物理空間的完整認知,這種與生俱來的空間理解能力是安全駕駛的核心基礎。然而當前行業普遍采用的2D視覺訓練模式,本質上如同僅憑行車記錄儀畫面就試圖駕馭復雜路況,存在根本性缺陷。
技術層面,傳統BEV架構在處理空間信息時存在高度維度缺失,而OCC方案雖能捕捉幾何結構卻無法解析語義信息。這種技術路徑導致AI系統始終無法真正理解三維世界的物理規律,成為制約自動駕駛發展的關鍵因素。李想形象地比喻:"現有方案就像讓AI戴著墨鏡看世界,既看不清立體結構,也讀不懂環境語義。"
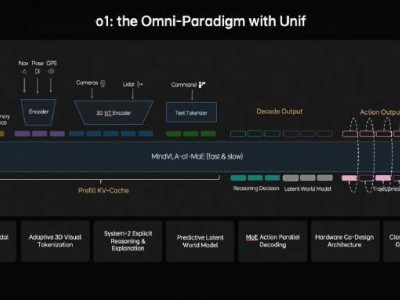
針對這一難題,理想汽車研發團隊推出原生3D ViT三維視覺編碼器。該技術突破性地將模型訓練直接置于三維空間進行,使系統能夠同步完成幾何結構解析與語義信息理解。配合自研馬赫芯片提供的三倍算力支持,新系統可實現500米以上的穩定環境感知,將激光雷達的角色從主傳感器轉變為高精度標定工具,顯著提升了系統冗余度。
更值得關注的是MindVLA?o1多模態大模型的創新應用。該模型通過統一建模空間理解、推理決策和駕駛行為,使系統具備"思考"能力。其獨特的隱空間模擬技術可提前預判場景變化,在復雜路況下實現更類人的決策邏輯。李想特別強調,這項技術突破不僅限于自動駕駛領域,其多模態架構已展現出適配機器人系統的潛力。
據技術文檔披露,原生3D架構使系統對動態障礙物的軌跡預測準確率提升42%,復雜路口的決策延遲降低至90毫秒以內。在夜間雨霧等極端天氣測試中,系統仍能保持98.7%的有效感知率。這些數據表明,理想汽車的技術路線正在重新定義自動駕駛的安全邊界。
隨著物理世界智能體概念的提出,理想汽車的技術布局顯現出更大野心。李想透露,公司正在開發基于該架構的通用AI平臺,未來將實現自動駕駛、家庭服務機器人、工業自動化等場景的跨領域應用。這種從單一交通場景向通用物理智能的延伸,標志著自動駕駛技術進入新的發展階段。