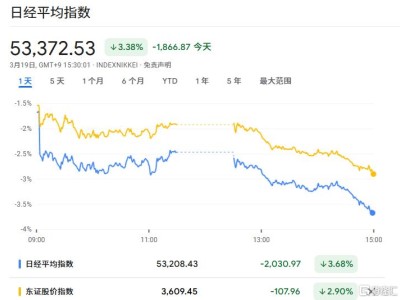
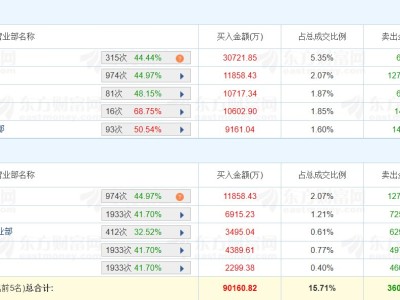
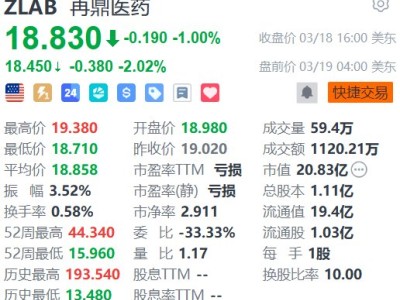
近日,理想汽車創始人李想發文直擊全球自動駕駛行業的痛點,深刻剖析了為何車企與科技公司投入巨資卻始終難以突破瓶頸的核心癥結。他指出,人類駕駛員的安全性源于幼年時期通過活動建立的完整3D物理空間認知,而行業主流方案卻長期停留在“偽3D”階段——即用2D視頻素材訓練AI。李想形象地比喻,這相當于駕駛員僅憑看行車記錄儀的畫面就上路,缺乏對真實物理世界的深度感知。
在李想看來,傳統的BEV架構容易丟失關鍵的高度信息,而OCC方案又往往缺失語義理解,導致AI始終無法像人類一樣真正“讀懂”三維世界,這成為了制約行業進展的關鍵瓶頸。
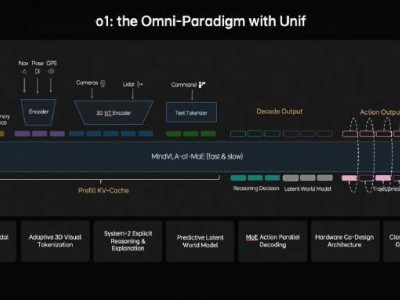
針對這一難題,理想汽車給出了顛覆性的技術破局方案。李想宣布,理想推出了核心突破——原生3D ViT三維視覺編碼器。該模型摒棄了從2D到3D的轉換過程,直接讓AI工作在3D空間中,實現了幾何結構與語義理解的同步完成。在自研馬赫芯片提供的三倍算力支撐下,這套系統可穩定感知500米以上的范圍,不僅大幅提升了感知精度,更讓激光雷達的角色發生轉變,降級為高精度標定工具。
理想推出的MindVLA-o1模型進一步實現了空間理解、推理決策與駕駛行為的統一建模。該模型具備多模態思考能力,能夠在隱空間內模擬場景變化,展現出類似人類的推理邏輯。李想強調,這一技術突破的意義不僅限于自動駕駛,它同樣適配機器人領域。自動駕駛只是“物理AI”的起點,理想正致力于打造通用的物理世界智能體,開啟人工智能與物理世界交互的新篇章。(Suky)