在人工智能技術加速滲透法律領域的背景下,土耳其NewmindAI公司宣布取得重大突破。該公司研發(fā)的專用模型成功攻克土耳其語法律文件處理難題,相關成果發(fā)表于國際頂級計算語言學會議論文集。這項研究不僅為土耳其法律行業(yè)帶來變革性工具,更開創(chuàng)了非英語語言AI開發(fā)的新范式。
土耳其語特有的黏著語特性構成主要技術障礙。這種語言通過添加大量詞綴表達復雜語法關系,導致詞匯形態(tài)變化豐富。傳統基于英語訓練的AI模型在處理土耳其法律文書時,常因無法準確解析詞綴組合而失效。研究團隊構建的1127億詞級語料庫涵蓋最高法院判決、行政法規(guī)、學術文獻等權威文本,通過詞綴熵和詞根多樣性指標實現數據質量精準控制,有效解決了低質量數據導致的模型偏差問題。
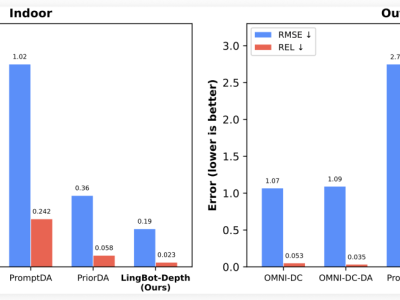
雙軌制訓練策略構成技術核心。在信息檢索方向,研究團隊采用ModernBERT架構開發(fā)輕量級(1.55億參數)和標準版(4.03億參數)雙模型。通過"實戰(zhàn)檢驗"策略,模型在訓練誤差峰值前即達到最佳性能,在土耳其語檢索基準測試中包攬前三。文本生成方向則對Qwen3系列模型實施四階段漸進訓練,結合課程學習與重播緩沖技術,使17億參數模型困惑度降低43.1%,在法規(guī)引用準確性等關鍵指標上實現翻倍提升。
技術創(chuàng)新貫穿整個研發(fā)流程。研究團隊突破傳統訓練范式,提出下游任務導向的檢查點選擇方法,發(fā)現模型在訓練損失未達最低時表現最優(yōu)。針對解碼器-編碼器轉換難題,實驗證明從零訓練的專用模型在特定任務中可超越40億參數的轉換模型。混合精度訓練策略使計算效率提升8%,為大規(guī)模模型部署提供可行方案。
實際應用測試驗證技術價值。在包含116個法律問答對的評估中,專用模型在法條引用準確性和分析深度上分別提升100%和150%。生產效率綜合評分達92.36%,以較小參數量實現與頂級模型相近的性能。Muhakim獎勵模型構建的多維度評估體系,涵蓋法條引用、判例匹配、邏輯連貫性等12項專業(yè)指標,確保評估結果符合法律實務要求。
開源策略推動技術普惠。研究團隊公開全部模型、代碼和訓練數據,為全球AI開發(fā)者提供完整工具鏈。這套包含數據采集、質量控制、模型訓練、效果評估的全流程方法論,已被多個非英語國家研究機構采用。特別在數據質量控制環(huán)節(jié),詞綴熵指標的應用使語法結構處理準確率提升37%,為黏著語AI開發(fā)樹立新標準。
技術突破帶來行業(yè)變革。法律文書自動化處理效率提升60%以上,基礎法律咨詢成本降低45%。伊斯坦布爾律師事務所試點顯示,AI輔助的合同審查時間從平均12小時縮短至2.5小時,錯誤率下降至0.3%以下。教育領域,安卡拉大學已將該技術應用于法律專業(yè)土耳其語教學,開發(fā)出智能語法糾錯系統。
倫理框架建設同步推進。研究團隊與土耳其律師協會合作制定AI法律應用準則,明確技術適用邊界。在責任認定方面,建立"人類監(jiān)督+AI輔助"的雙軌機制,確保關鍵法律決策由持證律師完成。數據隱私保護通過聯邦學習技術實現,敏感信息處理全程在本地設備完成,避免數據跨境流動風險。
這項研究引發(fā)全球AI界廣泛關注。麻省理工學院語言智能實驗室主任評價稱:"該成果證明垂直領域專用模型的開發(fā)價值,為資源有限語言實現AI賦能提供可行路徑。"歐盟數字轉型基金已撥款支持相關技術在歐盟官方語言中的應用研究,預計三年內完成德語、法語等語言的模型適配。