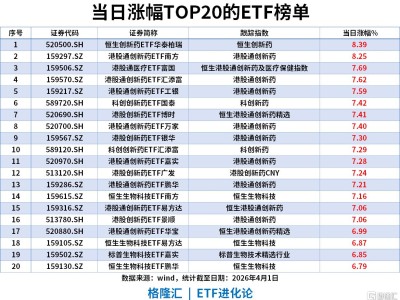
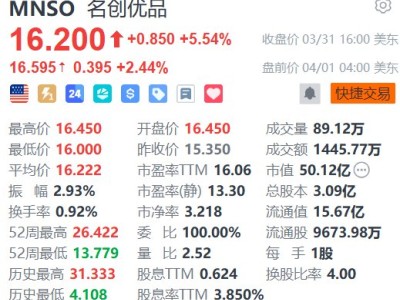
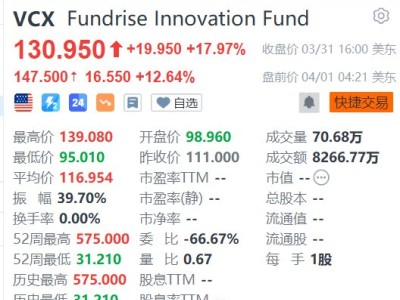
AIPress.com.cn報道
4月1日消息,谷歌研究人員Flip Korn和Chris Welty在一篇論文中提出了一套新的機器學習模型評估框架,重點解決AI基準測試中“每項評分需要多少人”的問題。這項研究基于“金標準”評分數據,旨在優化項目數量(N)與每項評分人數(K)之間的權衡,為構建高度可重復且能體現人類意見差異的AI基準提供系統方法。
在機器學習中,可重復性是衡量實驗可靠性的關鍵指標,指的是在相同代碼、數據分布和設置下重復實驗時能獲得相同結果的能力。高可重復性不僅能提升團隊間信任,也方便研究者在前人工作的基礎上進行拓展。然而,建立可重復的AI基準面臨的核心挑戰在于“人工標注數據的主觀性”。人類評審在面對同一問題時往往會有不同判斷,而現有的AI評測方法通常忽略這種差異,單純采用多數投票生成“單一真相”。這不僅無法反映人類意見的多樣性,也會影響評測結果的可靠性。
研究團隊通過模擬實驗,探索了在固定預算下,如何在“項目數量(N)”與“每項評審人數(K)”之間找到最優分配。他們將其比喻為“森林與樹”的策略選擇:
森林策略(breadth):讓更多不同的人評審更多的項目,側重廣度。
樹策略(depth):讓更多的人評審同一項目,側重深度。
傳統AI評測通常采用森林策略,每項項目僅由1至5名評審完成。然而,研究發現,這種低評審數量的做法既無法充分捕捉意見細微差異,也不能獲得整體趨勢的高可靠性結果。在某些任務中,為了全面理解人類意見的范圍,每項項目需要超過10名評審。
為驗證這一方法,研究團隊使用了多類數據集進行模擬實驗,包括:
Toxicity數據集:107,620條社交媒體評論,由17,280名評審標注毒性信息;
DICES數據集:350個聊天機器人對話,由123名評審從16個安全維度進行標注;
D3code數據集:4,554項跨文化內容,由4,309名評審從21個國家完成 offensiveness 標注,覆蓋不同性別和年齡層;
Jobs數據集:2,000條與就業相關的推文,每條由5名評審回答3個問題,涵蓋就業狀態、職位變化和信息角度。
在模擬過程中,研究團隊重點分析了兩方面:
規模(N):總評分項目數量,范圍從100到50,000;
人群(K):每個項目的評審人數,范圍從1到500。
通過數千種組合的模擬測試,團隊評估了不同N與K配置在統計可靠性和可重復性方面的表現。實驗顯示,合理調整每項項目的評審人數可以顯著提高p值的統計顯著性,從而更可靠地評估模型性能差異。
研究的核心發現包括:
傳統3–5名評審不足以捕捉人類意見:低評審數既無法體現意見廣度,也無法體現意見深度。每項項目通常需要超過10名評審以獲得高可重復性結果。
指標決定策略選擇:
若目標是匹配多數意見(Accuracy),森林策略更優,增加項目數量比增加評審人數更有效;
若目標是捕捉意見差異(Nuance),樹策略更優,通過增加每項評審人數來全面理解人類意見的分布。
效率可控:通過合理的N/K分配,即便總預算約1,000次標注,也能實現高可重復性結果。但錯誤分配即使增加預算也可能導致不可靠結論。
研究強調,隨著AI應用擴展到主觀性較強的領域,如倫理判斷、社交互動性質評估等,傳統“單一真相”假設已不再適用。在這些場景中,理解人類分歧的重要性與識別共識同樣關鍵。該研究提供了數學工具和模擬框架,幫助研究者設計既可靠又經濟的AI基準測試,確保實驗結果既能反映人類意見廣度,也能體現深度。
研究成果和模擬工具已開源,旨在支持AI研究社區,推動AI評測方法論和標準向更高可重復性與更好反映人類主觀差異方向發展。(AI普瑞斯編譯)