DeepSeek近日發布了面向OCR場景的專用模型DeepSeek-OCR 2,并同步公開了技術報告。這一模型在原有基礎上進行了升級,通過引入新型解碼器,使模型在處理圖像和文件時更接近人類閱讀習慣,而非傳統機械掃描方式。
傳統OCR模型通常采用從左上到右下的地毯式掃描模式,而DeepSeek-OCR 2則能夠理解文檔結構,按照邏輯順序逐步解析內容。這種改進使其在處理復雜布局、公式和表格時表現更佳。在文檔理解基準測試OmniDocBench v1.5中,該模型取得了91.09%的得分,較前代提升3.73%,在端到端OCR模型中達到領先水平,但仍略低于百度的PaddleOCR-VL管線。
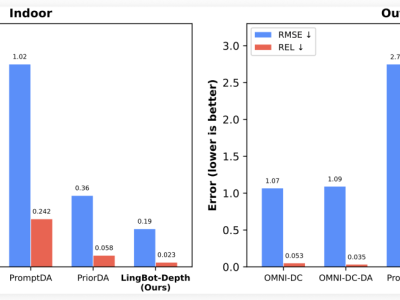
在視覺token效率方面,DeepSeek-OCR 2在相似預算下,文檔解析的編輯距離低于Gemini-3 Pro,證明其在保持高性能的同時實現了更高的視覺信息壓縮率。該模型不僅可作為新型視覺語言模型(VLM)架構的研究工具,還能生成高質量預訓練數據,支持大語言模型訓練。
從技術架構看,DeepSeek-OCR 2延續了編碼器-解碼器結構,但將編碼器從DeepEncoder升級為DeepEncoder V2。新編碼器采用基于大語言模型(LLM)的設計,通過因果流查詢機制實現視覺標記的語義重排序。這一過程不依賴固定位置編碼,而是讓模型根據全局視覺上下文動態生成順序,更符合人類認知習慣。
DeepEncoder V2通過視覺tokenizer實現約16倍的token壓縮,在降低計算資源消耗的同時保留關鍵視覺信息。其核心創新在于因果查詢機制:每個查詢可訪問所有視覺標記及先前查詢結果,在保持token數量不變的前提下完成語義排序和信息蒸餾。最終僅有序查詢結果被輸入解碼器,形成編碼器與解碼器的兩級因果推理流程。
模型訓練分為三個階段:編碼器預訓練、查詢增強和解碼器專業化。預訓練階段使編碼器掌握特征提取和token重排序能力;查詢增強階段進一步提升重排序精度和視覺知識壓縮效率;解碼器專業化階段通過凍結編碼器參數優化解碼效率。實驗采用OmniDocBench v1.5基準,包含1355個中英文文檔頁面,覆蓋雜志、學術論文等9個類別。
測試結果顯示,DeepSeek-OCR 2在最小視覺標記上限設置下達到91.09%的準確率,閱讀順序編輯距離從0.085降至0.057。在1120個視覺標記預算下,其文檔解析編輯距離(0.100)優于Gemini-3 Pro(0.115)。不過,該模型在處理高密度報紙文本時表現稍遜,可通過增加局部裁剪或擴充訓練樣本改善。
DeepSeek-OCR 2的架構設計為多模態編碼器發展提供了新思路。研究團隊認為,這種基于LLM的編碼器有望演變為統一處理文本、語音和視覺內容的全模態編碼器,通過共享參數空間實現不同模態信息的有效壓縮與重組。此次發布標志著原生多模態探索的重要進展,為后續VLM架構研究奠定了基礎。