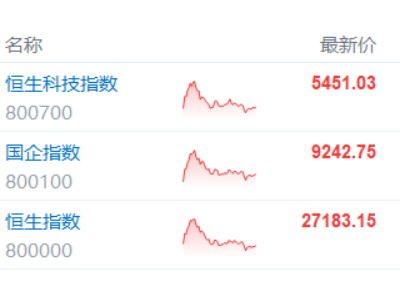
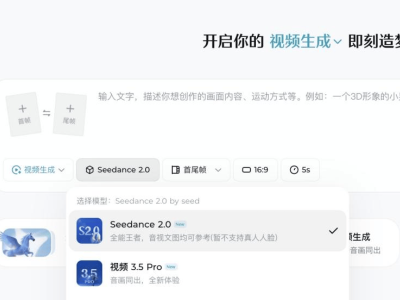
快手公司近日宣布,其自主研發(fā)的新一代視頻生成模型可靈3.0系列已進(jìn)入超前內(nèi)測階段。該系列包含圖片3.0、視頻3.0及視頻3.0 Omni三個(gè)子模型,在原有技術(shù)基礎(chǔ)上實(shí)現(xiàn)了多項(xiàng)突破性升級,旨在為影視創(chuàng)作、廣告設(shè)計(jì)等領(lǐng)域提供更專業(yè)的生成式AI解決方案。
圖片3.0模型的核心升級聚焦于專業(yè)創(chuàng)作場景的適配性。通過引入視覺思維鏈(vCoT)技術(shù),該模型可對輸入圖像進(jìn)行結(jié)構(gòu)化解構(gòu)推理,支持單圖或多圖批量生成邏輯連貫的系列畫面。輸出分辨率方面,新增2K與4K選項(xiàng),滿足影視預(yù)演、場景設(shè)定等高精度需求。針對AI生成內(nèi)容常見的細(xì)節(jié)斷裂問題,研發(fā)團(tuán)隊(duì)通過Deep-Stack視覺信息流機(jī)制優(yōu)化了紋理與光影的過渡效果,同時(shí)強(qiáng)化了對構(gòu)圖比例、鏡頭視角等參數(shù)的控制精度,使生成畫面更符合專業(yè)創(chuàng)作規(guī)范。
在模型訓(xùn)練環(huán)節(jié),快手創(chuàng)新性地采用強(qiáng)化學(xué)習(xí)框架,結(jié)合"真實(shí)感"與"電影質(zhì)感"雙重評估體系,通過數(shù)百萬組專業(yè)影視素材的對比學(xué)習(xí),顯著降低了生成內(nèi)容的機(jī)械感。技術(shù)文檔顯示,該模型在人物面部特征、物體材質(zhì)等細(xì)節(jié)還原上已達(dá)到行業(yè)領(lǐng)先水平,特別在復(fù)雜光影場景下的表現(xiàn)力較前代提升40%以上。
視頻3.0模型則構(gòu)建了統(tǒng)一的多模態(tài)訓(xùn)練框架,支持文本、圖像、視頻片段的混合輸入。單次生成時(shí)長擴(kuò)展至15秒,并允許用戶在3-15秒?yún)^(qū)間自由調(diào)整。智能分鏡系統(tǒng)成為最大亮點(diǎn),該系統(tǒng)可自動(dòng)解析文本指令中的場景轉(zhuǎn)換需求,智能調(diào)度特寫、中景、全景等景別切換,配合動(dòng)態(tài)機(jī)位調(diào)整功能,使生成視頻具備專業(yè)分鏡腳本的敘事邏輯。
針對影視創(chuàng)作中的核心痛點(diǎn),視頻3.0模型在主體一致性控制方面取得突破。通過多圖/視頻錨定技術(shù),用戶可鎖定特定角色的面部特征、服裝細(xì)節(jié)或物體形態(tài),確保在復(fù)雜運(yùn)動(dòng)場景中保持視覺連貫性。音畫同步模塊新增五國語言及方言支持,采用深度神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)口型與語音的毫秒級匹配,在多人對話場景中可精準(zhǔn)區(qū)分角色發(fā)聲,文字生成模塊則通過超分辨率技術(shù)確保字幕清晰可辨。
作為高端版本,視頻3.0 Omni引入視頻主體特征庫功能,可提取3-8秒視頻中的角色形象、動(dòng)作特征及音色數(shù)據(jù),建立可復(fù)用的數(shù)字資產(chǎn)庫。該技術(shù)通過特征解耦重組方案,實(shí)現(xiàn)形象、聲音、動(dòng)作的分離存儲與靈活調(diào)用,為影視IP開發(fā)、虛擬偶像運(yùn)營等場景提供技術(shù)支撐。音頻處理方面,創(chuàng)新性的采樣區(qū)間調(diào)整算法使音色還原度提升至92%,在跨語言內(nèi)容生成中仍能保持聲線特征穩(wěn)定。