AIPress.com.cn報道
2月14日,字節跳動宣布豆包大模型正式進入2.0階段。
這次發布的核心思路很明確:隨著AI進入Agent時代,大模型不再只是回答問題,而是要在真實世界中執行復雜任務。豆包2.0圍繞這個方向做了系統性優化,強化了高效推理、多模態理解和復雜指令執行三項核心能力。
豆包2.0系列包含四款模型。Pro版面向深度推理和長鏈路任務,官方表態是全面對標GPT 5.2和Gemini 3 Pro。Lite版在性能和成本之間取平衡,綜合能力超越上一代主力模型豆包1.8。Mini版面向低延遲、高并發和成本敏感的場景。Code版專門為編程場景優化,和字節自家的AI編程產品TRAE配合使用效果更好。
目前豆包2.0 Pro已經在豆包App、電腦端和網頁版上線,用戶切換到"專家"模式就可以體驗。Code版已接入TRAE。面向企業和開發者,火山引擎也已經上線了全系列的API服務。
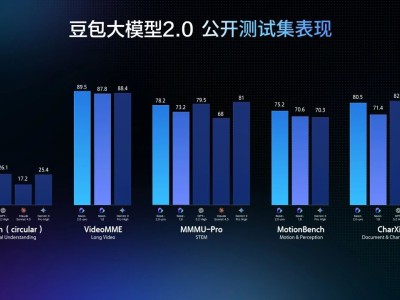
先看多模態能力。豆包2.0在視覺理解任務上的表現達到了全球頂尖水平,視覺推理、感知能力、空間推理和長上下文理解尤為突出。Pro版在大多數相關基準測試中拿到了最高分。
在動態場景理解方面也有明顯進步。豆包2.0強化了對時間序列和運動感知的處理能力,在TVBench等關鍵評測中領先,在EgoTempo基準上甚至超過了人類得分。這意味著它對變化、動作、節奏這類時序信息的捕捉更加穩定,在實際應用中的可靠性更高。
長視頻場景是另一個亮點。豆包2.0在多數長視頻評測上超越了其他頂尖模型,在流式實時問答基準中表現也很好。實際應用場景包括實時視頻流分析、環境感知、主動糾錯和情感陪伴。舉個例子,它可以在你健身或試穿衣服時實時提供反饋和建議,從被動問答升級為主動指導。
再看語言模型和Agent能力。要在真實世界執行長程任務,模型需要廣泛而深入的知識儲備。豆包2.0在長尾領域知識上做了重點加強。結果是,Pro版在SuperGPQA上的得分超過了GPT 5.2,在HealthBench上拿到了第一名,在科學領域的整體成績與Gemini 3 Pro和GPT 5.2相當。
推理和競賽方面的成績也很亮眼。Pro版在IMO和CMO數學奧賽、ICPC編程競賽中獲得金牌成績,在Putnam Bench上超過了Gemini 3 Pro。在HLE-text(被稱為"人類的最后考試"的評測)上拿到了最高分54.2分。工具調用和指令遵循測試中也表現出色。
不過跑分之外,豆包2.0可能最具競爭力的一點是定價。官方表示,模型效果與業界頂尖水平相當,但token定價降低了大約一個數量級。在Agent時代,復雜任務的執行往往涉及大規模推理和長鏈路生成,會消耗大量token,成本差異在這種場景下會被急劇放大。便宜十倍意味著企業在相同預算下可以處理十倍的任務量,或者用十分之一的成本達到相同的效果。
Agent能力方面,字節展示了一個基于OpenClaw框架和豆包2.0 Pro構建的智能客服案例。這個客服Agent部署在飛書上,能通過調用不同技能完成客戶對話。碰到自己解決不了的問題,它會主動拉群求助真人同事。它還能幫客戶預約上門維修人員,維修完成后主動回訪,順便推薦春節優惠產品。整個流程不是預設的固定腳本,而是根據實際情況動態決策。
Code模型的演示同樣值得一看。字節用TRAE加豆包2.0 Code搭建了一個叫"TRAE春節小鎮·馬年廟會"的互動項目。這個場景相當復雜:11個性格各異的NPC由大語言模型驅動,會根據人設自然聊天、招呼客人、現場砍價。AI游客們像真人逛廟會一樣,自己決定去哪個攤位、買什么、說什么。煙花升空時的祝福語、孔明燈上的四字題詞都由AI實時生成,每次進入小鎮看到的互動都不一樣。
整個項目只用了一輪提示詞完成基礎架構和場景搭建,再經過幾次調試,總共五輪提示詞就完成了。相關的提示詞和素材已經開源在GitHub上。