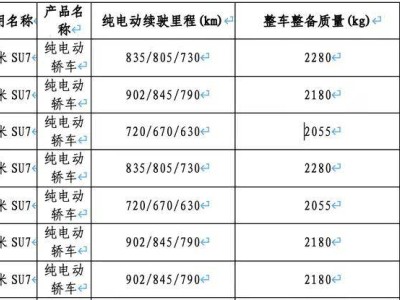
月之暗面核心團隊近日在社交媒體平臺Reddit上舉辦了一場備受矚目的有問必答活動,三位聯合創始人楊植麟、周昕宇和吳育昕與全球網友展開深度交流,話題涵蓋模型技術、行業趨勢以及公司發展等多個方面,從凌晨持續到凌晨三點,解答了眾多關鍵疑問。
活動伊始,就有網友提出尖銳問題,質疑Kimi K2.5自稱Claude是對其進行蒸餾的證據。楊植麟解釋,這是由于預訓練階段對最新編程數據上采樣,而這些數據與“Claude”這個token關聯性強,并且強調K2.5在多個基準測試中表現優于Claude。對于備受期待的Kimi K3,楊植麟雖未透露過多細節,但表示會在Kimi Linear基礎上加入更多架構優化,即便沒有比K2.5強10倍,也肯定會強很多。
在算力儲備問題上,當被問及與其它企業的GPU數量差距在2026年是否會縮小時,楊植麟直言差距并未縮小,實現通用人工智能(AGI)所需的算力還有待觀察。周昕宇則補充道,可用算力受多種因素影響,創新往往誕生于約束之中。
針對技術架構相關問題,有網友詢問對DeepSeek的Engram架構的看法及是否考慮采用。周昕宇認為對嵌入進行Scaling是值得探索的方向,但在測試前缺乏可靠數據。對于訓練大規模模型如何界定沉沒成本,周昕宇表示會將實驗結果分享給技術人員深入討論,以決定項目的走向。團隊鼓勵質疑,每天都會進行相關討論。同時,團隊憑借對技術基本面的準確判斷,在長期研究中取得不錯成果,關鍵在于擁有“把事情真正做成并落地”的共同價值觀。
在模型訓練挑戰方面,楊植麟稱訓練視覺語言模型(VLM)的主要挑戰在于同時提升文本和視覺性能,不過二者可相互促進。對于開發自己的編程工具Kimi Code的原因,他表示需要一個與模型最匹配的框架,且Kimi Code有視頻輸入等獨有功能,video2code代表著前端開發的未來。在強化學習基礎設施方面,吳育昕介紹團隊力求在保持靈活性的同時實現高效率,智能體蜂群部署邏輯復雜,但系統靈活性高,可集成不同框架和子智能體設置。
關于Scaling階梯,周昕宇表示從非常小的規模開始實驗,核心目標是預測系統的可擴展性。有些架構、優化器和數據無法擴展,在低FLOPs下評估可擴展性需要深刻理解訓練過程的數學動態。例如,Kimi Linear移植到K2中時曾出現Scaling失敗,經過數月調試才達到現有水平,研究重點在于應對失敗。
在模型性能與應用方面,對于Kimi K2.5的算力分配,楊植麟認為強化學習的計算量將持續增長,未來可能出現更多新的目標函數用于強化訓練。針對有人探索架構遞歸實現P/poly復雜度的問題,他表示當前架構下許多問題在計算上可解,模型能力瓶頸在于任務可驗證性,智能上限取決于新學習算法。對于K2.5自稱Claude的現象,他進一步解釋在正確系統提示詞下會回答“Kimi”,系統提示為空時反映預訓練數據分布。K2.5在多個基準測試中優于Claude。對于降低K2的幻覺問題,吳育昕稱通過提高數據質量和獎勵機制改善,但仍有改進空間。關于K2.5使用較高參數比例是否“浪費”計算資源,吳育昕和周昕宇認為過度訓練是為了獲得更優整體權衡而主動支付的成本。
在“智能體蜂群”功能上,吳育昕介紹該功能中各子智囊團可獨立執行子任務,擁有各自工作記憶,只在必要時返回結果給調度器,擴展了整體上下文長度。對于權衡強化編程能力與非編程能力,楊植麟表示在模型參數規模足夠的情況下二者不存在根本性沖突,但保持“寫作品味”是挑戰,團隊依賴內部基準評測調整獎勵模型。對于K2.5個性變化問題,吳育昕承認每次新版本發布模型“個性”會有變化,正在努力解決以滿足用戶個性化需求。
對于Kimi K3的規劃,楊植麟表示正在嘗試新架構和新功能。對于是否采用新架構及如何保留K2.5 Thinking性能,他肯定了線性架構,希望在Kimi Linear基礎上加入更多架構優化,相信K3會有顯著提升。對于在線/持續學習計劃,周昕宇稱持續學習可提升模型自主性,Kimi Linear是與K2.5并行開展的項目,線性注意力機制是未來模型關鍵方向。在模型角色塑造方面,楊植麟認為模型核心在于“品味”,K2.5有獨特審美取向,其性格也是“品味”體現,較少迎合用戶或許是好的性格特征。對于是否開源“智能體蜂群”或添加到Kimi-cli中,楊植麟表示目前處于測試階段,穩定后會向開發者提供框架。對于視覺編碼器大小問題,吳育昕稱小型編碼器有利于Scaling。對于是否推出帶原生音頻輸入功能的模型,楊植麟表示目前資源有限,可能重點放在訓練更好的智能體上。