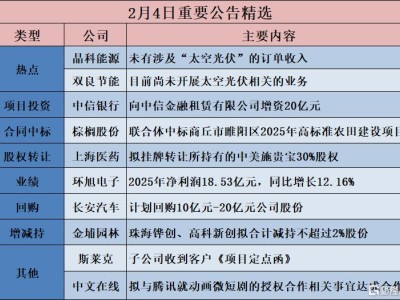
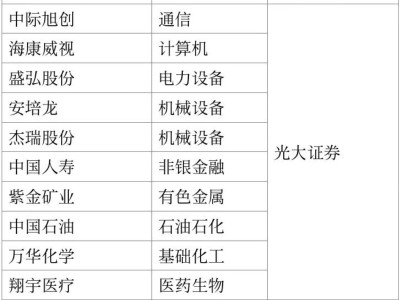
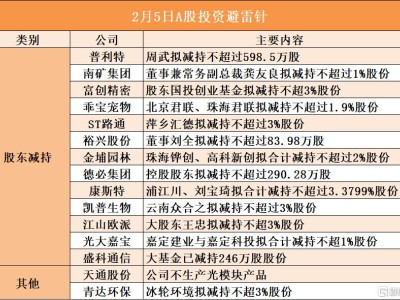
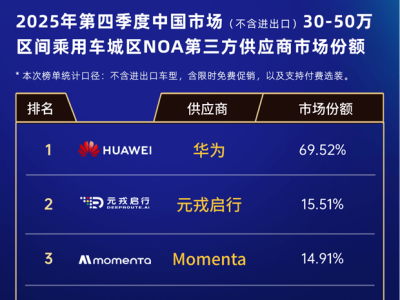
在大型語言模型訓練領域,一項突破性研究為提升效率、降低成本帶來了全新解決方案。香港某高校科研團隊提出名為Mano的優化器,通過創新設計顯著優化了大模型訓練過程,在性能提升與資源消耗控制方面取得雙重突破。
傳統訓練方法面臨兩大核心矛盾:既要處理參數間的復雜關聯,又需控制計算資源消耗。當前主流的AdamW優化器如同逐題批改的教師,雖能處理單個參數卻忽視整體結構;而Muon優化器雖嘗試統一處理所有維度,卻因丟失曲率信息導致優化效果受限。研究團隊通過重構優化邏輯,創造性地將訓練過程轉化為動態幾何探索,使模型參數在平滑數學表面自主尋找最優路徑。
Mano的核心機制在于"旋轉斜流形"設計,通過交替進行列向與行向歸一化操作,實現多維參數空間的立體化探索。具體而言,該優化器在奇數訓練輪次執行列方向歸一化,偶數輪次切換至行方向,這種動態調整策略使模型能夠從不同角度解析參數關系。實驗數據顯示,在LLaMA-350M模型訓練中,Mano的收斂速度較Muon提升1.75倍,在1.3B參數規模下仍保持1.38倍的優勢,且隨著模型規模擴大,性能差距進一步拉大。
資源消耗控制方面,Mano展現出顯著工程優勢。其內存占用與SGD動量法相當,僅為AdamW的50%,在70B參數規模的LLaMA模型訓練中,注意力層歸一化耗時僅2.19毫秒,較Muon的110.79毫秒降低超98%。這種效率提升源于其避免復雜矩陣運算的設計,每次參數更新僅需11mn次浮點運算(m、n為矩陣維度),而Muon的Newton-Schulz迭代計算量呈指數級增長。
理論層面,研究團隊證明Mano的交替歸一化過程等價于Sinkhorn-Knopp迭代算法,可確保矩陣收斂至雙隨機矩陣,從而保證優化穩定性。頻譜分析顯示,該優化器在提升稀有方向更新幅度的同時,完整保留奇異值原始排序,這種結構化處理方式有效避免了Muon因白化操作導致的信息丟失。梯度穩定性測試進一步證實,Mano在相同動量系數下,梯度方差降低40%,信噪比提升25%,為持續優化提供可靠保障。
實際應用中,Mano展現出極強的適應性。其實現僅需設置學習率、動量系數和權重衰減三個參數,超參數調優復雜度低于AdamW。對于一維偏置參數,團隊建議沿用AdamW優化,形成混合優化策略。研究團隊還開發了高維張量版本,通過循環遍歷各維度實現通用化處理,支持Transformer等復雜架構的參數優化。
與現有方法的對比實驗揭示了Mano的獨特價值:在訓練初期,AdamW憑借自適應學習率實現快速收斂;中期Muon通過頻譜歸一化展現優勢;而Mano在后期持續保持穩定下降趨勢,最終模型性能超越兩個基準優化器。這種訓練階段特異性優勢,使其特別適用于需要深度優化的超大規模模型訓練場景。
該研究重新激活了流形優化在深度學習領域的應用潛力。通過將經典數學理論與現代工程實踐結合,團隊證明適當改造的傳統方法仍能解決前沿技術難題。這種研究范式為優化器設計提供了新思路:在追求算法創新的同時,深度挖掘現有理論的改造空間,往往能產生兼具理論美感與實用價值的解決方案。