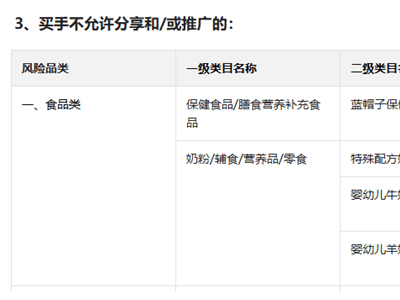
在人工智能蓬勃發展的當下,數據已成為驅動企業創新與轉型的核心要素。如何高效治理數據、釋放AI潛力,成為企業數智化升級的關鍵命題。亞馬遜云科技成長型企業及新興業務總經理倪殿令在近期媒體溝通會上,通過生動的比喻揭示了數據治理在AI應用中的底層邏輯,引發行業關注。

倪殿令將AI數據處理流程比作餐館運營:農場運來的食材需經清洗、分類、切配(對應Amazon EMR服務),處理后的食材按類別存入冰箱(向量數據庫如Amazon Aurora、Amazon RDS),當顧客點餐時(AI查詢請求),廚師從冰箱取材烹飪(模型調用與計算)。他強調:"AI應用的性能90%取決于底層數據處理能力。企業能否駕馭生成式AI,核心在于數據規模與質量,而非前端模型或應用界面。"
針對企業落地AI的實踐路徑,倪殿令提出"黃金三角"方法論:首先需精準定位高價值業務場景,如智能客服、知識庫構建等,明確輸入輸出標準;其次要構建結構化數據基礎,通過數據治理工具實現非結構化數據向向量的轉化;最后需配備數據工程師、算法工程師等專業人才,完成模型適配與調優。他特別指出:"開源模型如同通用教材,企業需通過微調(Fine-tuning)注入行業知識,通過蒸餾技術提煉關鍵能力,才能形成差異化競爭力。"
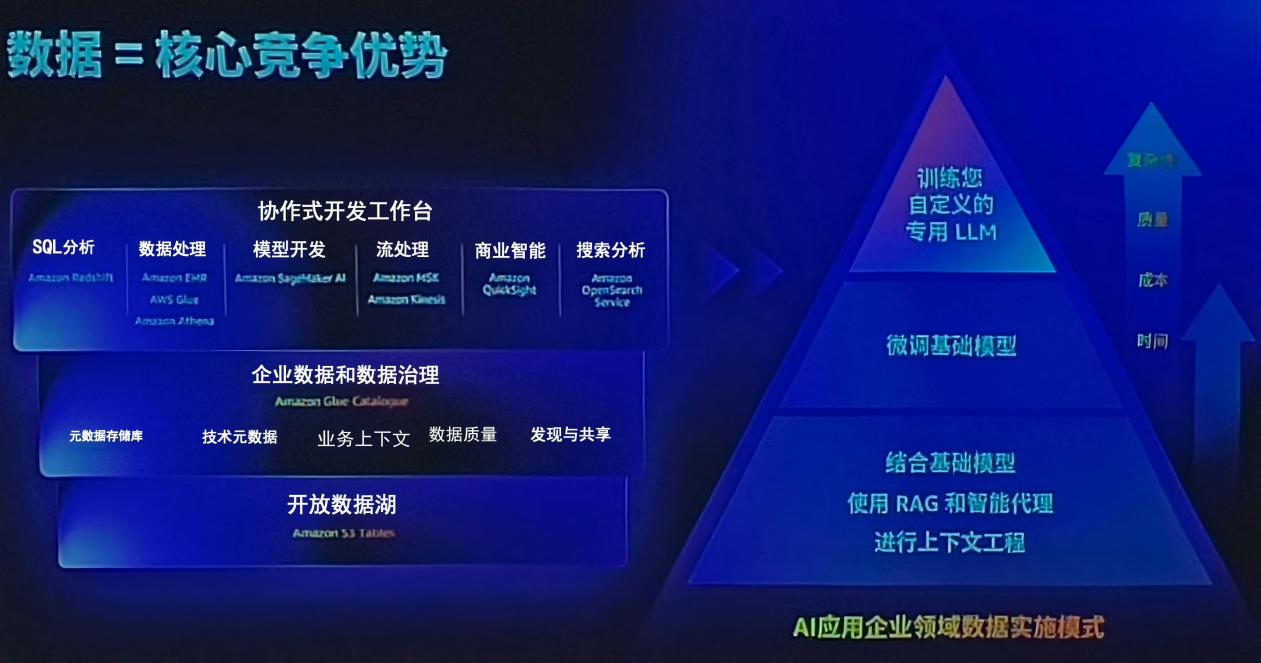
據技術白皮書顯示,亞馬遜云科技的數據治理方案已形成完整閉環:從數據采集階段的EMR治理,到存儲層的向量數據庫支持,再到應用層的RAG增強檢索架構,覆蓋了AI全生命周期。這種技術積累使其在IDC最新評估中位列中國生成式AI數據基礎設施市場領導者象限,其服務已助力多家企業實現查詢響應速度提升60%、模型幻覺率降低40%的顯著效果。
當前,數據治理正從后臺支持角色轉向戰略核心。隨著企業AI應用從試點走向規模化,如何平衡數據安全與利用效率、如何構建跨部門數據協作機制,將成為下一階段競爭焦點。亞馬遜云科技的實踐表明,只有筑牢數據根基,才能讓AI技術真正轉化為商業價值。